Быстрая настройка Яндекс.Директ с помощью конструктора UTA-manager
ВидеоинструкцияПерейти в конструктор
Цель этого руководства - помочь специалистам и новичкам по контекстной рекламе разобраться в тонкостях работы конструктора UTA-manager. Который, в свою очередь, помогает сэкономить время на настройке контекстной рекламы в 3-4 раза по сравнению со стандартным сценарием настройки.
Разберем конкретный пример настройки кампании для сайта по продаже ковриков для йоги одного из наших клиентов. Это одностраничный сайт, на котором продается несколько видов товаров для любителей йоги.
Добавление семантики в конструктор
Будем считать, что семантическое ядро уже собрано. Теперь собранные фразы нужно добавить в конструктор UTA-manager. Сделать это можно двумя способами:
1. Копировать-вставить
Копируем фразы, нажав кнопку “Копировать”, выбираем пункт "Копировать без частотности". Либо, если еще не пользуетесь сервисом вордстат, копируете в буфер фразы из другого места.
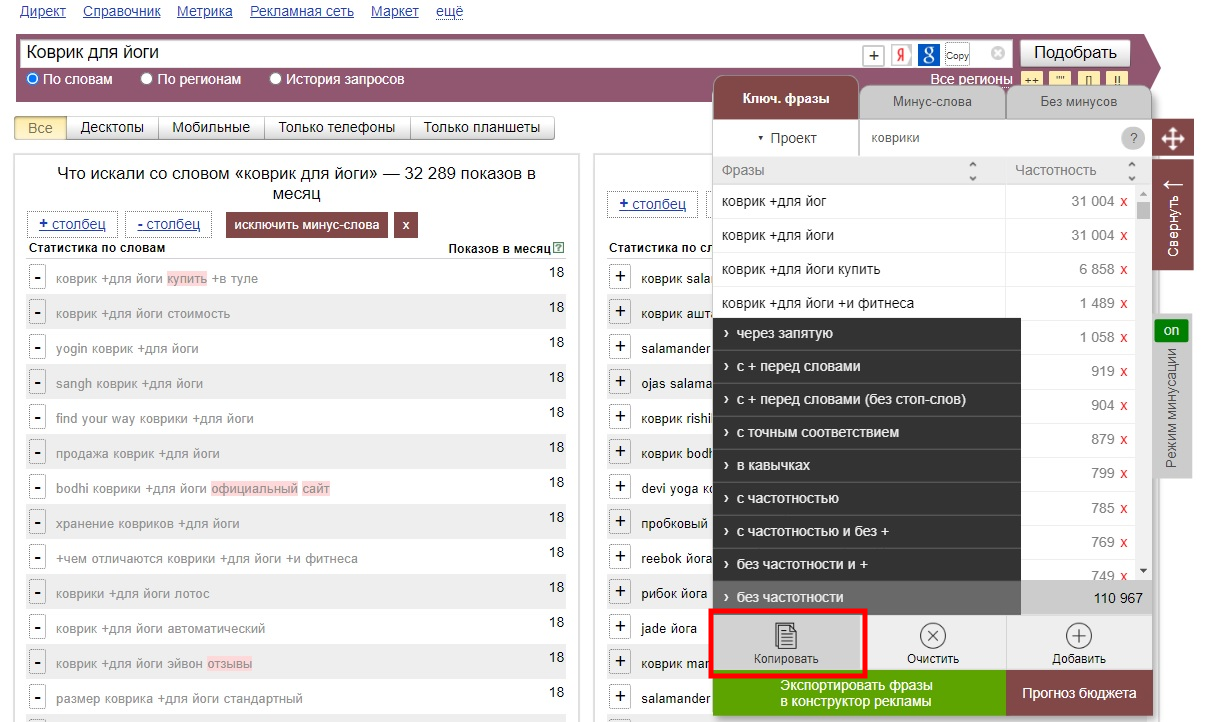
Затем переходим в конструктор и нажимаем кнопку “Создать”, обозначенную значком "+":
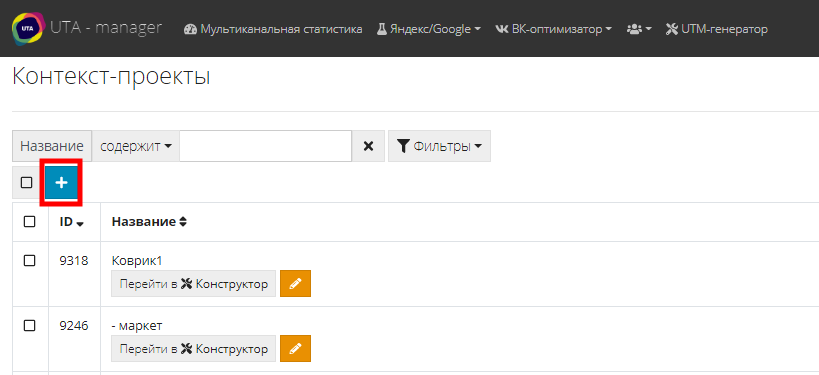
Откроется меню добавления нового проекта, куда и добавляем скопированные фразы (1). Вводим название проекта(2), ставим галочку “Удалить дубли” (3) и жмем “Создать”:
2. Добавление напрямую из Wordstat.
Если пользуетесь вордстатом, то cможете добавить не только фразы, но и собранные минус-слова в конструктор одной кнопкой.
Нажимаем большую зеленую кнопку. Если проект еще не сохранен, Wordstater предложит это сделать:
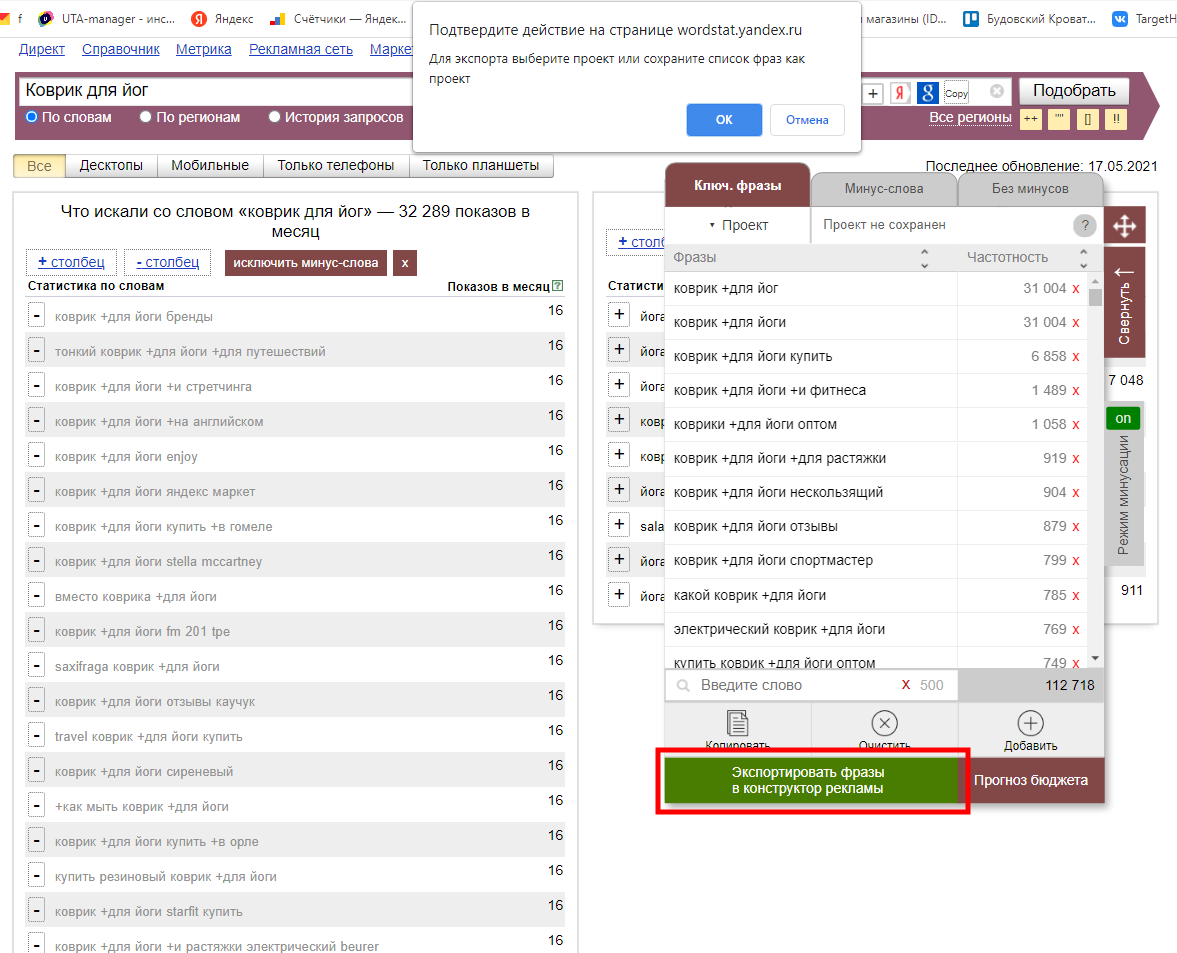
Нажимаем “Проект” -> "Сохранить как", вводим имя и жмем "ОК":
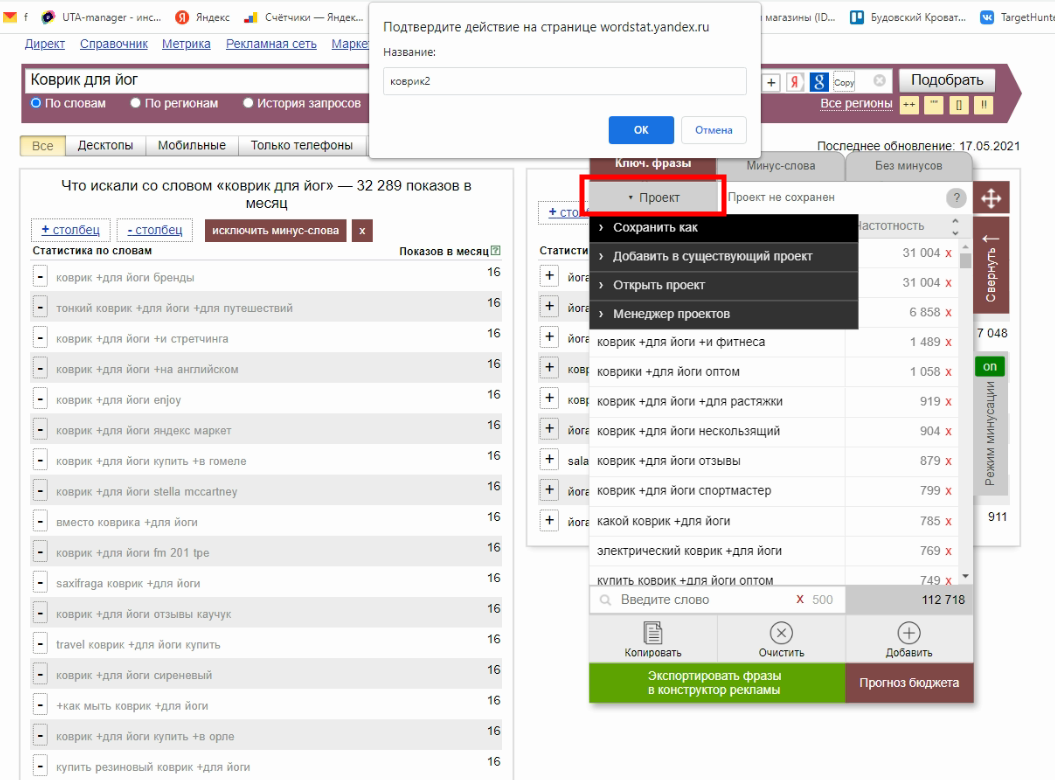
Жмем еще раз на зеленую кнопку. В появившемся меню соглашаемся с созданием нового проекта, и после сохранения фразы попадают сразу в конструктор, а именно в меню "Создание проекта".
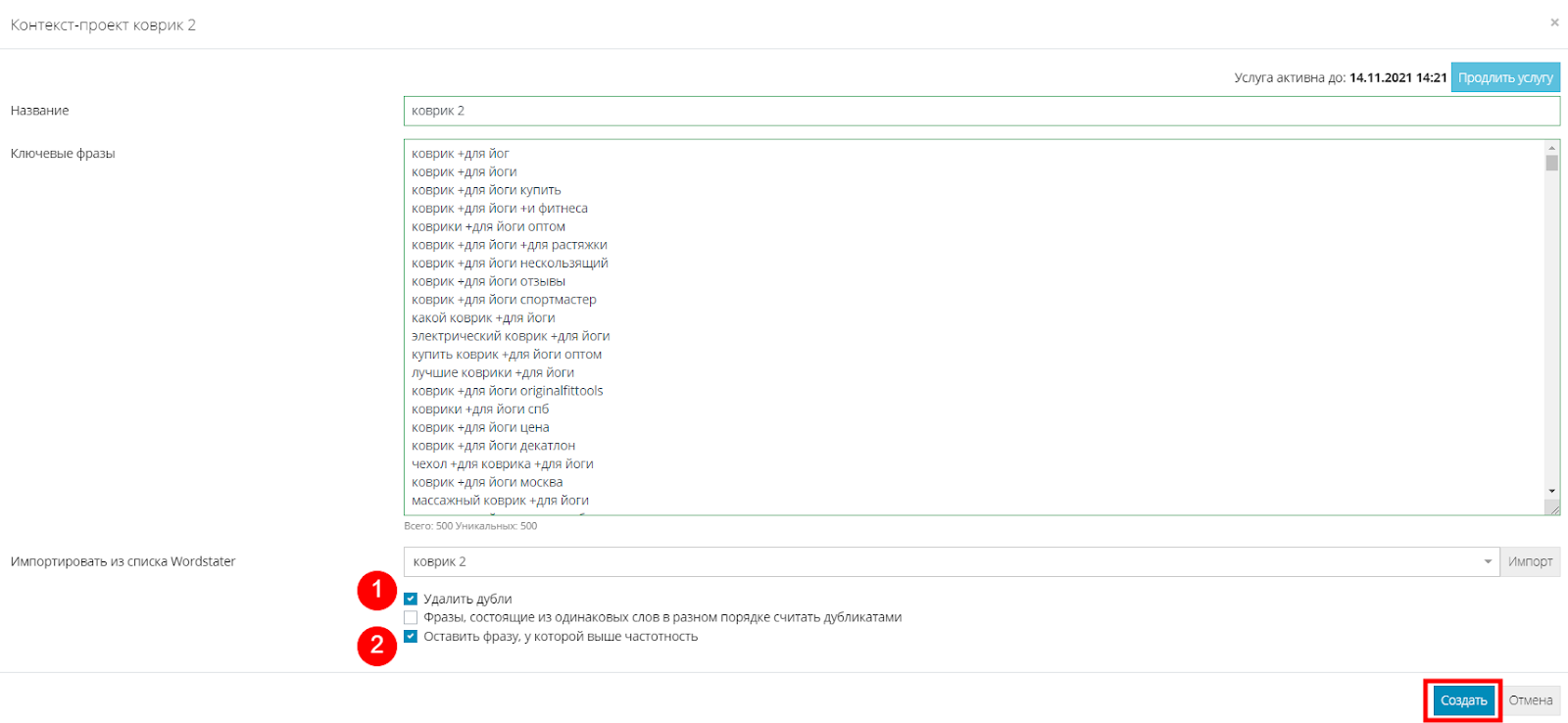
Остается только поставить галочку на “Удалить дубли” (1). Дополнительно можете поставить галочку на “Оставить фразу, у которой выше частотность” (2). В этом случае конструктор соберет частотность дубликатов из вордстат и оставит фразу с большей частотностью. На это может потребоваться дополнительное время.
Жмем “Создать”, и начнется поиск дубликатов:
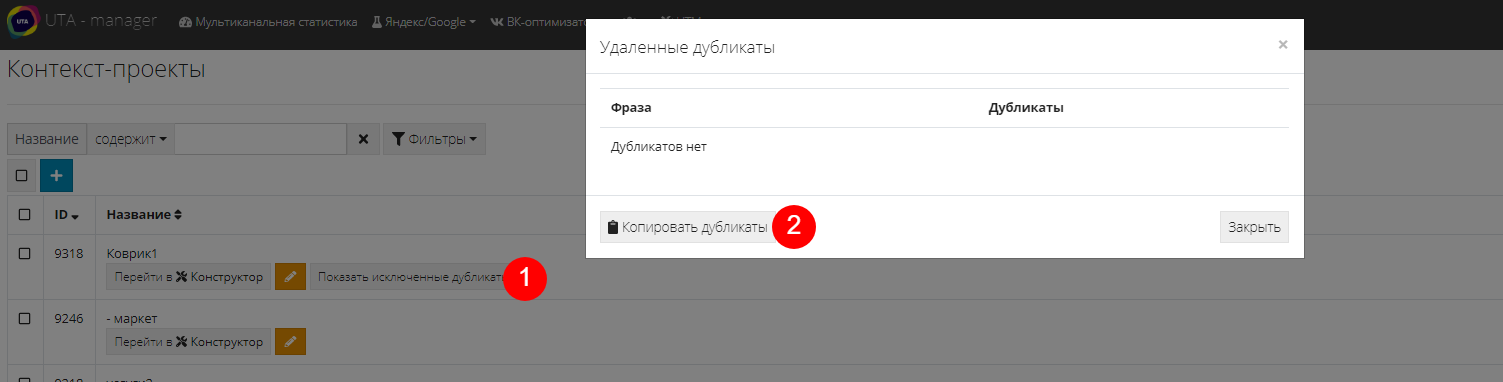
После этого можно нажать кнопку “Показать исключенные дубликаты” (1), и если не согласны с конструктором, то можете скопировать их (2) и вставить обратно в проект:
Знакомство с интерфейсом
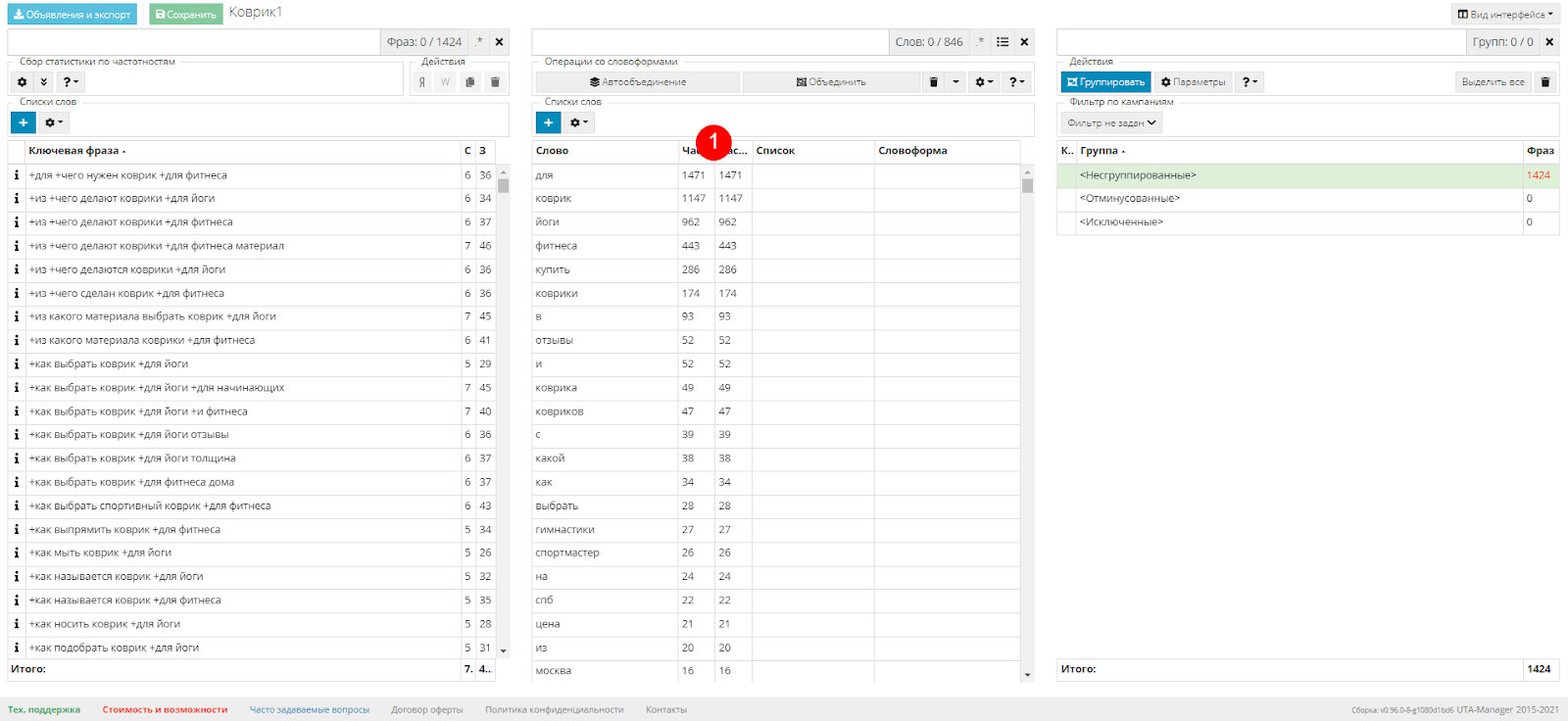
Интерфейс конструктора состоит из трех таблиц.
Левая - это таблица ключевых фраз. В ней отображаются ключевые фразы. Посередине расположена таблица слов. Система разбивает все фразы на отдельные слова и добавляет их в эту табличку. Цифры рядом со словами (1) показывают, в скольких фразах встречается это слово для выделенной группы или для всей семантики. Кликая по слову, в левой табличке сразу же отобразятся все фразы с этим словом, и тогда можно оценить насколько оно целевое. Но об этом позже.
В правой таблице будут отображаться составленные в последствии группы:
Сбор статистики по фразам
В первую очередь соберем статистику по фразам, чтобы можно было опираться на нее при группировке. Для этого жмем на шестеренку в таблице ключевых фраз:
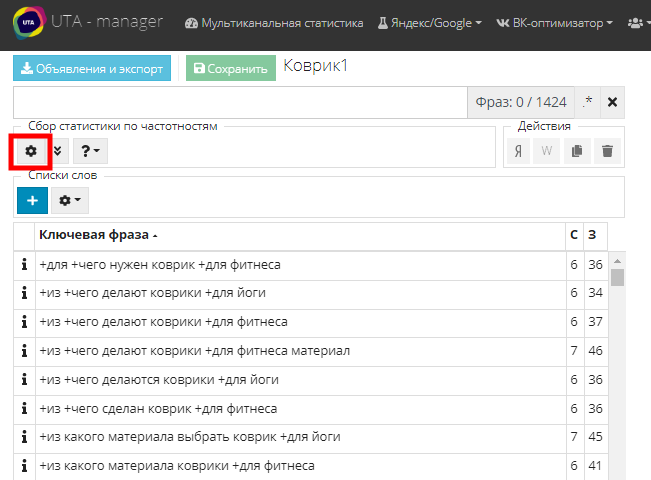
Откроется окно параметров сбора статистики. В первой строке выбираем целевой регион или населенный пункт. В нашем случае это вся Россия. Во второй строке выбираем столбцы со статистикой, которые должны отображаться рядом с фразой. С их полным списком сможете ознакомится в процессе будущей работы с конструктором. Сейчас же нам понадобится столбец WS (означает общую частотность по фразе), “WS” (означает частотность в точном соответствии). И добавим Клики, чтобы знать прогноз кликов по каждой фразе.
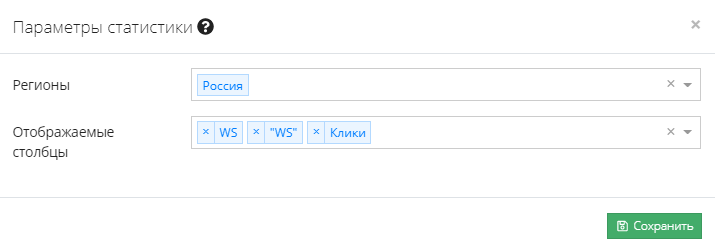
После сохранения нажимаем на кнопку рядом с шестеренкой, это инициирует сбор статистики. В зависимости от количества фраз сбор статистики может длиться от 1 до 10 минут.
Автообъединение словоформ
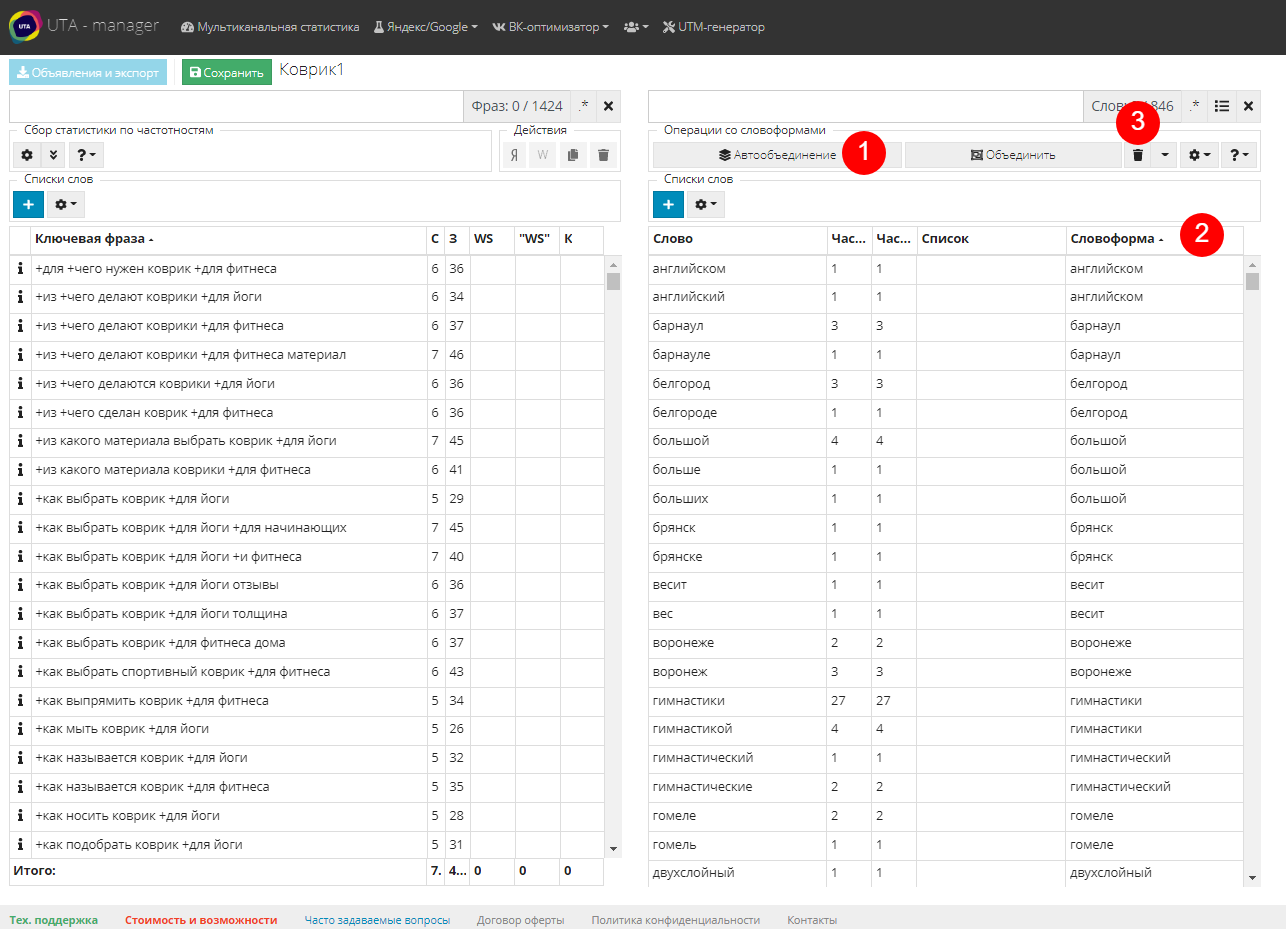
Пока собирается статистика, объединим словоформы слов, чтобы было проще с ними работать. Для этого в таблице слов жмем кнопку “Автообъединение” (1). Система мгновенно проанализирует и объединит похожие слова в словоформы. Затем, чтобы просмотреть их, сортируем список по столбцу "Словоформы" (2). Если были объединены разные по смыслу слова, то выделите это слово и нажмите на значок с корзиной (3). Это удалит слово из объединенной словоформы.
Рекомендуем объединять словоформы именно в начале работы с семантикой, т.к. дальше мы будем вручную объединять слова, а автообъединение сбрасывает все прошлые группировки.
Ручное объединение словоформ
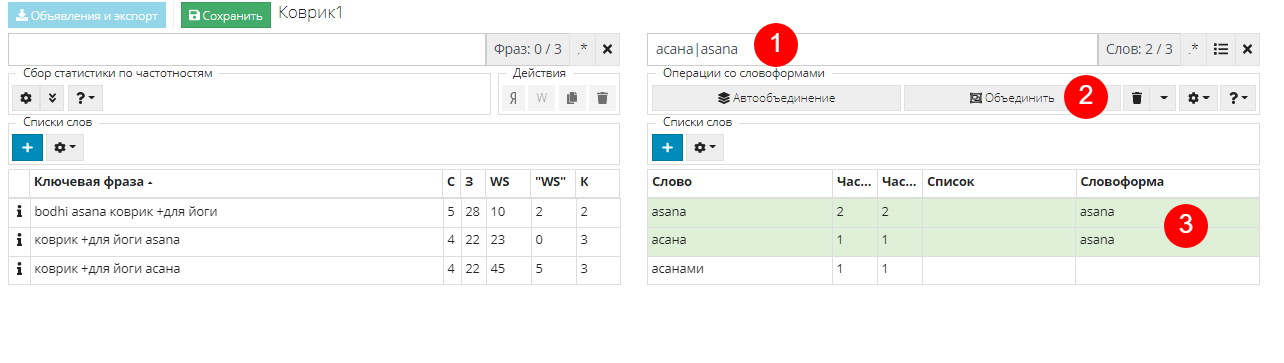
После автообъединения, которое объединяет похожие слова, необходимо проверить близкие по смыслу слова, которые могут писаться по-другому. Приведу пример на названии бренда. Сайт продает коврики бренда Asana, и мы знаем, что его могут искать как на русском, так и на английском языке. Поэтому ищем такие слова в ключевых фразах. В строке поиска (1) можем сразу прописать все варианты написания через оператор или - |. Система выдала три подходящих слова, два из которых нужно объединить, а третье нам не подходит из-за другого смысла фразы.
Зажимаем клавишу CTRL и выделяем нужные слова, затем жмем на кнопку "Объединить" (2). Теперь этим фразам присвоена одна словоформа, о чем свидетельствует запись в соответствующей колонке (3):
Объединение позволит собрать в одну группу близкие по смыслу фразы. Это могут быть:
- Количественные показатели, которые пишутся по-разному. Например: размер 1,2 м. и 120 см.
- Одинаковые по смыслу слова. Например: дешево и недорого.
И многие другие характеристики, которые, по вашему мнению, не требуют отдельной группы ключевых фраз.
Создание списка минус-слов
Теперь начнем очищать семантическое ядро. Для этого будем добавлять определенные слова из ключевых фраз в различные списки.
Первым создадим список минус-слов. Для этого нажимаем на кнопку "+" на панели списка слов, которая располагается над первой и второй таблицей. В появившемся окне вводим его название, например: “минуса” и жмем “Создать”:
Добавлять слова в список можно разными способами. Разберем их по порядку.
1. Добавление слов в список из таблицы слов
В этом случае стандартный алгоритм действий будет таким:
-
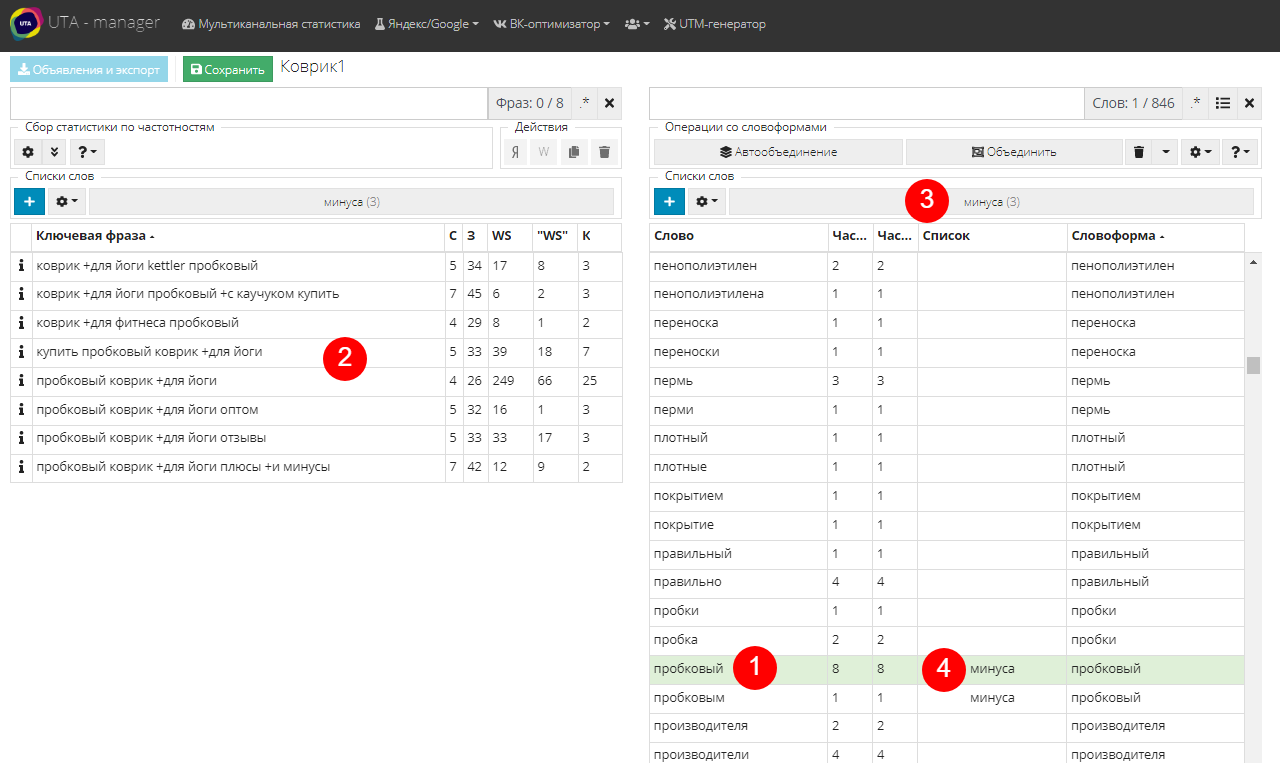
Просматриваем список слов и, найдя неподходящее, кликаем по нему. В нашем случае это “пробковый” (1)
-
Слева в таблице появится список фраз с этим словом. Убеждаемся, что это неподходящие нам фразы (2)
-
Заносим это слово в список, нажав на название списка (3). Теперь напротив него в столбце "Список" будет отображаться название списка, к которому оно принадлежит (4).
-
Помним, что если мы добавили в список одно слово из группы словоформ, в него же добавятся и все остальные объединенные слова. В нашем случае добавляется “пробковым”.
2. Добавление минус-слов с помощью многостраничного фильтра
Это инструмент, который позволяет отфильтровать фразы по указанному списку слов. Это краткое описание. Более подробно работа фильтра описана здесь.
Чтобы его открыть, нажимаем на соответствующую кнопку:
Откроется фильтр, который можно использовать множеством способов.
2.1 Добавление собственного списка минус-слов
Если Вас уже есть собранный список минус-слов из другой похожей кампании, тогда можно простым копированием перенести его в многостраничный фильтр. Только учитывайте, что слова должны идти в столбик. Жмем “Применить”:
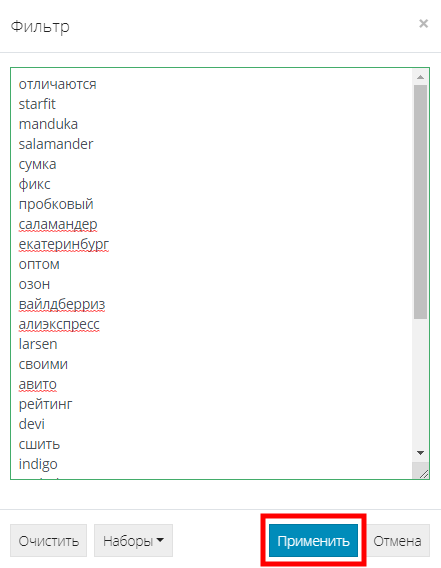
Фильтр найдет совпадения с этим списком и выведет найденные слова в списке слов. Таким образом можно добавить сразу несколько разных слов в список. Для этого с зажатой клавишей "SHIFT" выделяем первое и последнее слово из списка и отправляем их в минуса нажатием на название списка (1):
2.2 Фильтрация по наборам слов
В многостраничный фильтр уже встроено несколько наборов слов по разным категориям. Это различные города, станции метро. Слова, относящиеся к оптовикам, отзывам, ремонту и т.д. Воспользуемся одним из них. Переходим в многостраничный фильтр. Нажимаем “Наборы” и выберем “Вопросы”. Появится список вопросительных слов, с помощью которого можно отфильтровать фразы справочного характера. Жмем "Применить", найденные слова отфильтруются. Можем также выделить их с зажатой клавишей "SHIFT" и добавить всей кучей в список.
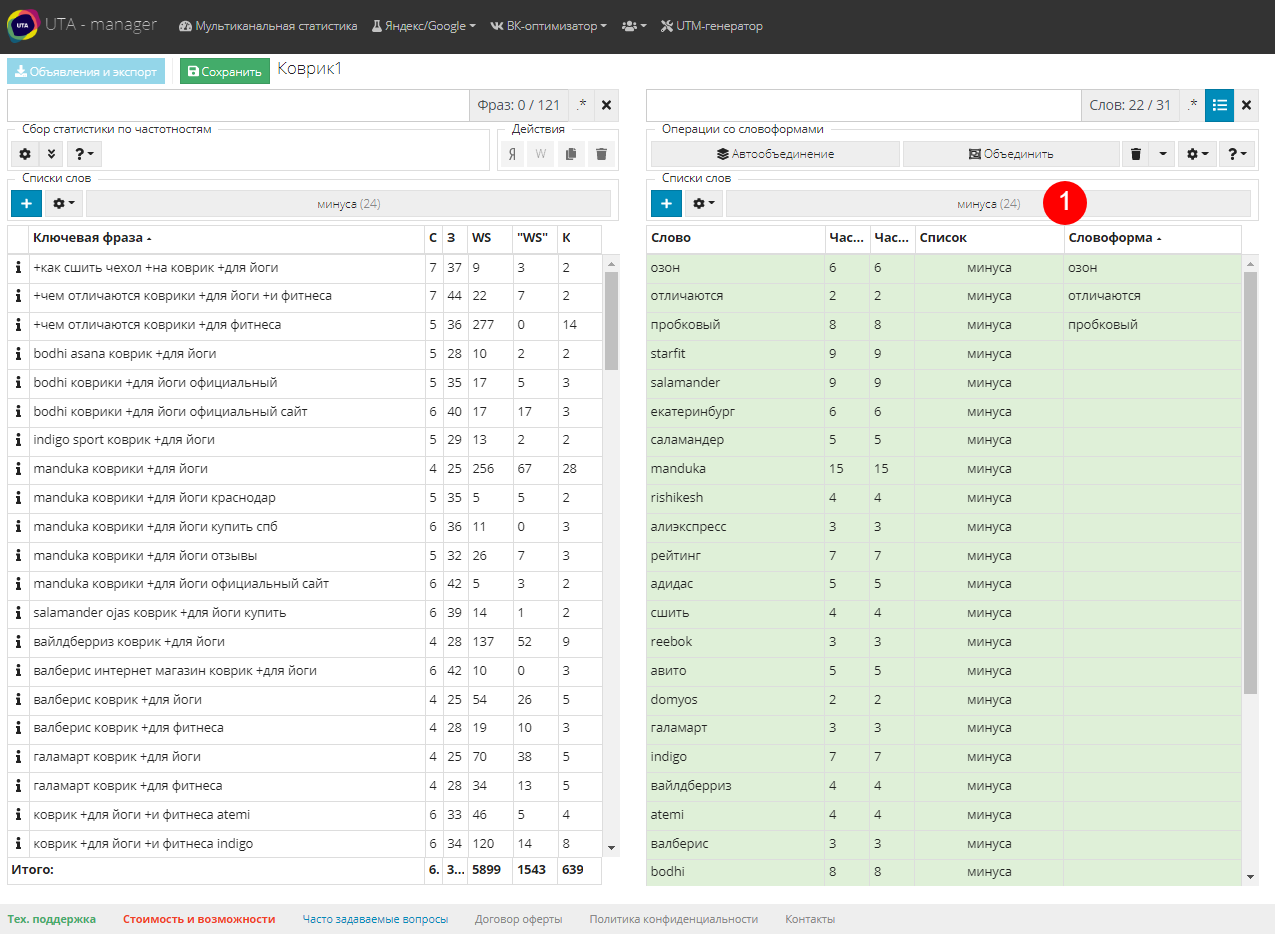
3. Добавление минус-слов из таблицы фраз
Из этой таблицы слова в список можно добавлять в один клик. Для этого нужно активировать список кликнув по нему (1). Теперь все слова во фразах станут кликабельными. Красным подсвечиваются слова, которые уже есть в списке. Кликаем по нужным словам и добавляем их в список. Например, слова: “делают”, “сделан”, “мыть” и др. Чтобы удалить слово из списка, нажимаем на выделенное слово еще раз.
Этот режим дополняет описанные выше, так как позволяет пополнить список минус-слов для лучшей фильтрации трафика. Ведь этот список можно будет добавить прямиком в кампанию. Например, на скриншоте выделены слова вопросительной формы, но во фразах с ними есть и другие нецелевые слова, которые мы и добавили в этом примере.
Минусация нецелевых словоформ
Часто случается так, что одна или несколько словоформ могут вести нецелевой трафик, тогда как остальные - вполне целевые. Их можно будет добавить в список минус-слов кампании с оператором фиксации словоформы - !.
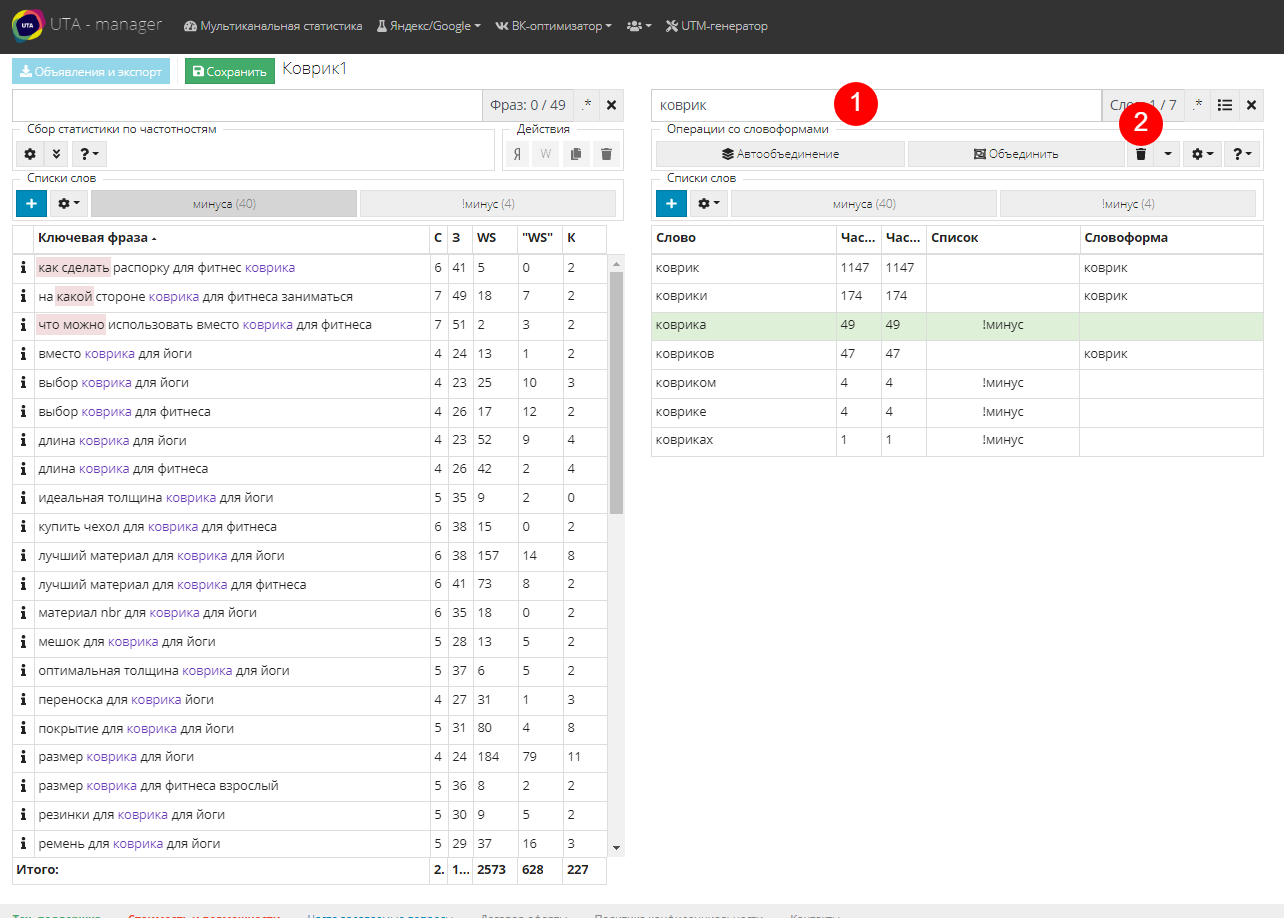
Рассмотрим на примере слова “коврик”. Оно является основным и встречается в каждой собранной фразе. Вводим в фильтре слово "коврик" (1). Кликаем по каждой словоформе и смотрим на смысл фраз с нею. “Коврик” и “коврики” это точно целевые слова, дальше интереснее. Видим, что словоформа “коврика” содержит фразы со смыслом дополнительных аксессуаров для них, уходом и других непродающих смыслов. Поэтому создаем новый список слов “!минус” и добавляем в него это слово, предварительно отделив его от других словоформ нажатием на корзину (2). Аналогичным образом проверяем остальные словоформы:
Быстрая проверка фраз с незнакомым смыслом
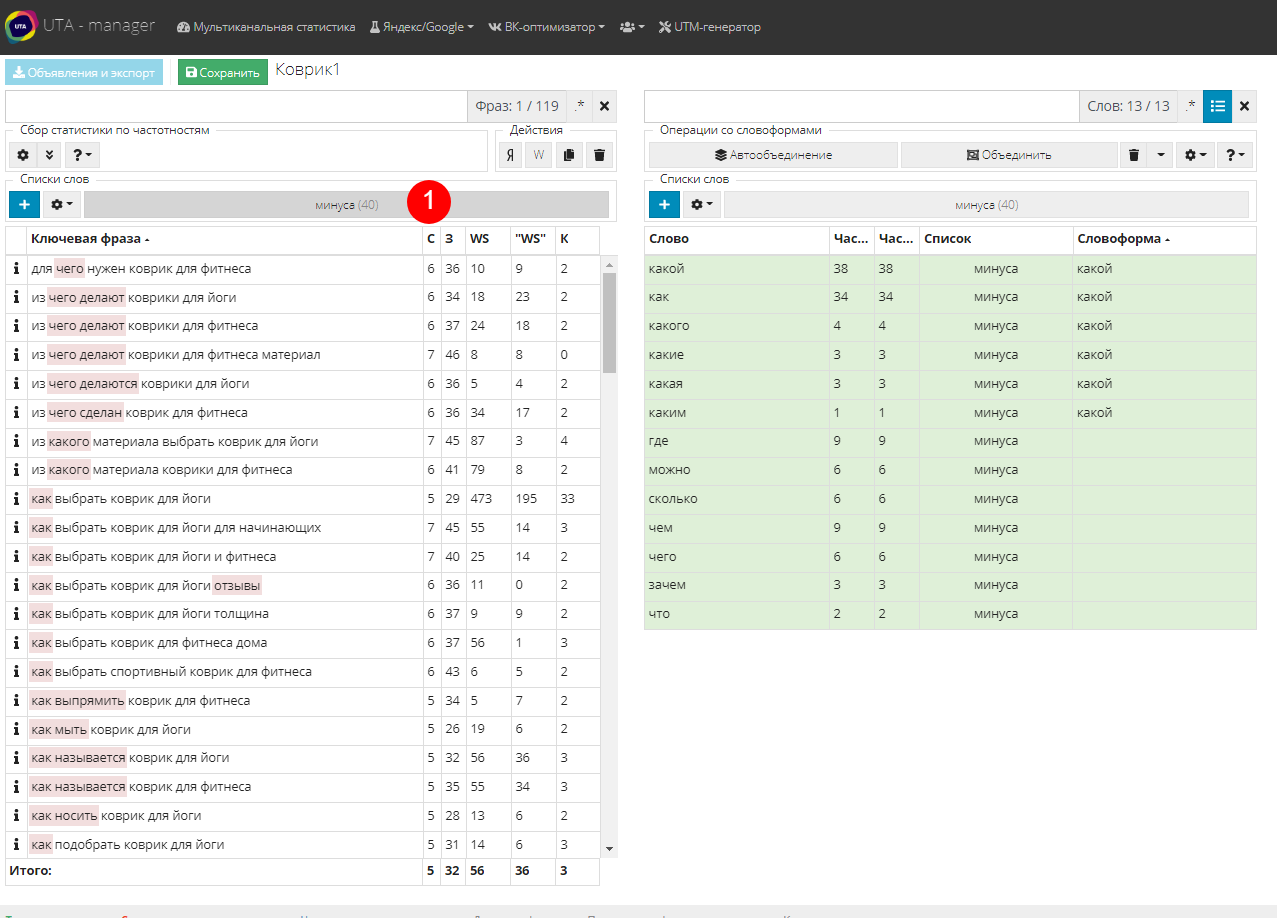
При работе с семантикой часто случается так, что смысл фразы непонятен. Нет четкого понимания - целевая она или нет. Самым простым способом это выяснить может быть проверка фразы в поисковых системах или через Wordstat. В конструкторе UTA-manager заложен такой функционал.
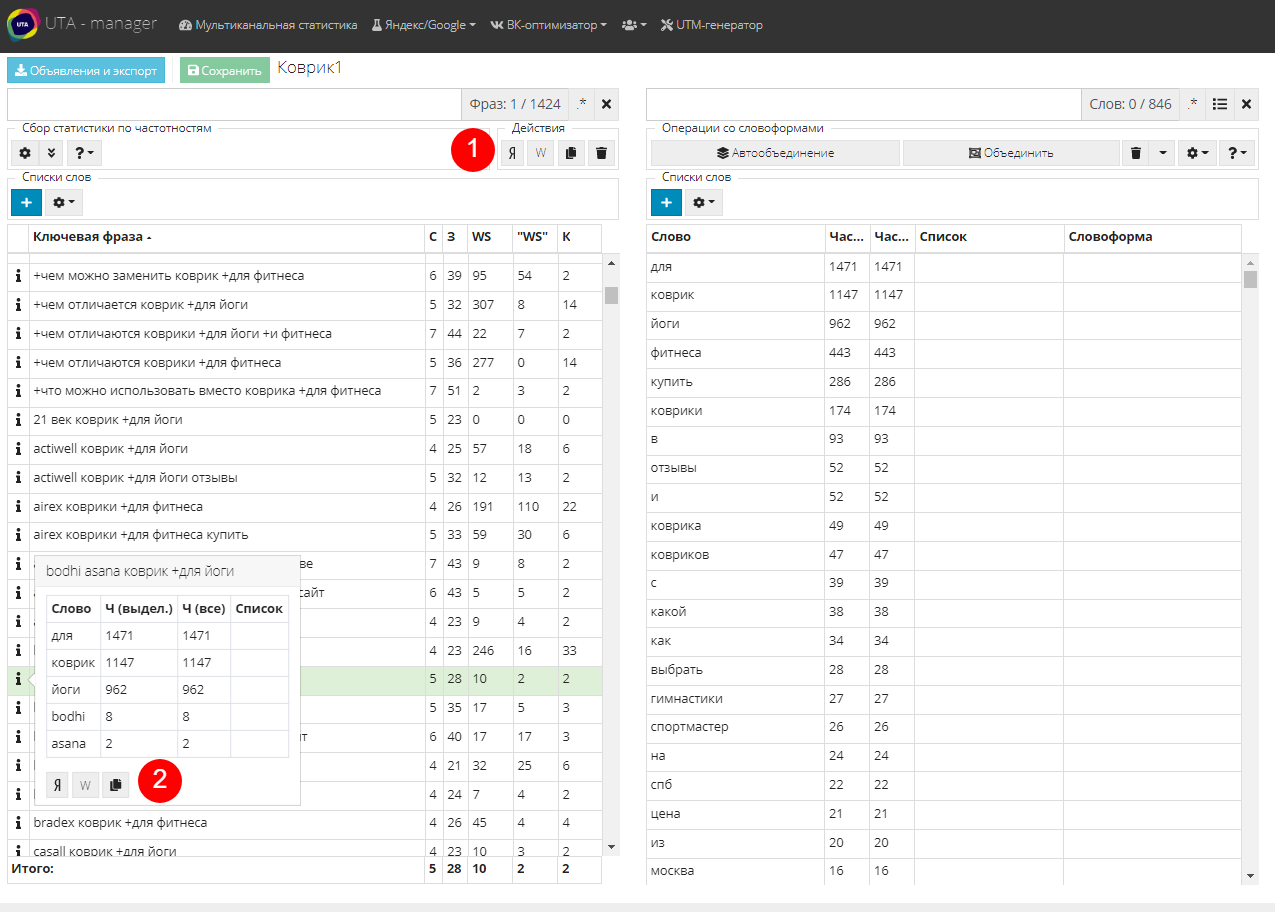
В таблице ключевых фраз выделяем непонятную фразу и нажимаем на кнопку “Я” на панели действий, что означает поиск в Яндексе (1). Нас сразу же перекидывает на страницу Яндекс с уже введенной фразой в поисковую строку. Поиск по Wordstat в этом случае будет полезен, чтобы посмотреть, какие еще варианты этой фразы люди вводят в поисковиках. Для этого нажимаем “W”.
Другим способом проверить фразу можно через панель информации о фразе. Нажмите на значок “i”, который располагается слева от каждой фразы, откроется всплывающее окно. В нем кроме информации о каждом слове, как в таблице слов, есть также кнопки перехода на поиск Яндекс, Wordstat или кнопка копирования фразы в буфер (2).
Выделяем фразы с городами в отдельную группу
В зависимости от тематики сайта, фразы с указанием города города могут быть как самыми горячими, так и околоцелевыми. Если это товар, то чаще всего они означают поиск офлайн-магазина. На этапе очистки семантики рекомендуем выделить эти фразы в отдельную группу для дальнейшей работы с ними.
Сделать это можно в несколько кликов с использованием многостраничного фильтра. Открываем его с помощью уже знакомой нам кнопки в строке поиска. Кликаем по кнопке “Наборы” и видим, что здесь есть списки не только по городам и населенным пунктам, но также по районам и станциям метро крупных городов. Выбираем нужный нам, например, "города РФ", и жмем "Применить":
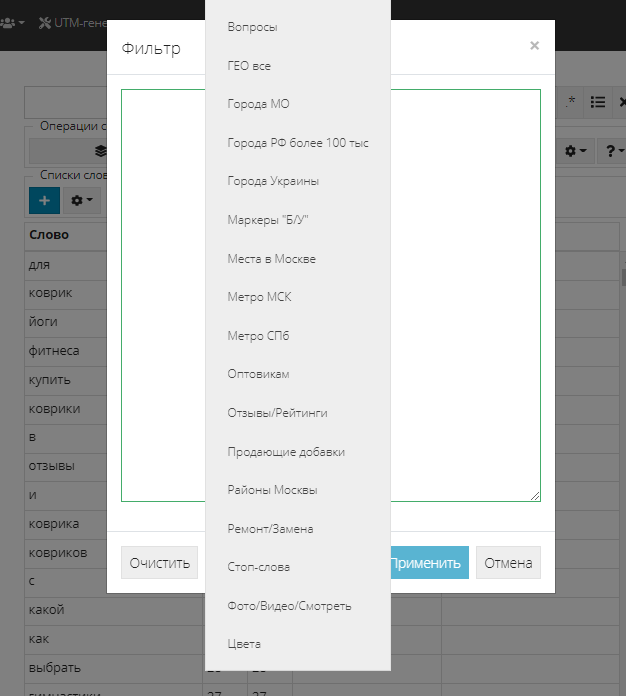
Фильтр выделит найденные слова из списка. Создаем новую группу слов, называем ее “города”. Выделяем все отфильтрованные слова и определяем их в этот список, кликая по нему.
Выделение фраз с конкурентами в отдельные группы.
На первом этапе тестов фразы с конкурентами не рекомендуем использовать. Зато потом, когда рекламные кампании уже набирают обороты, можно добавить их в отдельную кампанию и создать контратакующие объявления или предложить более выгодные условия. В любом случае, сейчас их нужно отделить от основной массы целевых фраз. Поэтому создаем для них отдельный список.
Выделяем фразы для уточнения у клиента
Бывают такие фразы, по которым сразу не скажешь - подходит оно или нет. Например: у нас есть фраза “коврик для йоги для занятий в кроссовках”. Сразу и не скажешь - можно ли заниматься на них в кроссовках или нет. Такая фраза требует уточнения у клиента. Создаем для таких фраз отдельный список и после обработки семантики составляем ряд вопросов для уточнения.
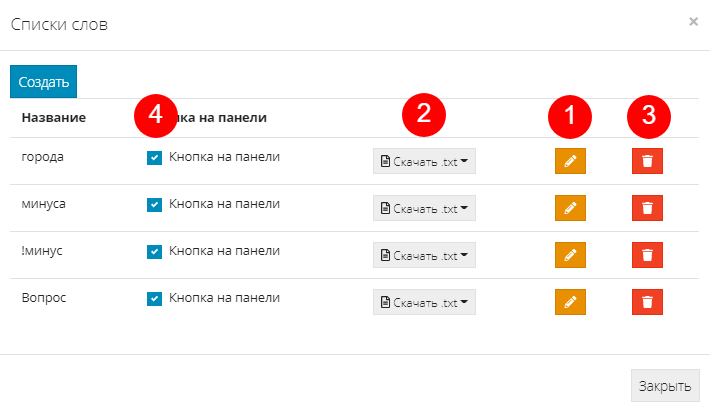
Как скачать список слов
Чтобы скачать список, нажимаем на шестеренку рядом с кнопкой добавления и выбираем “Редактировать/скачать список”:
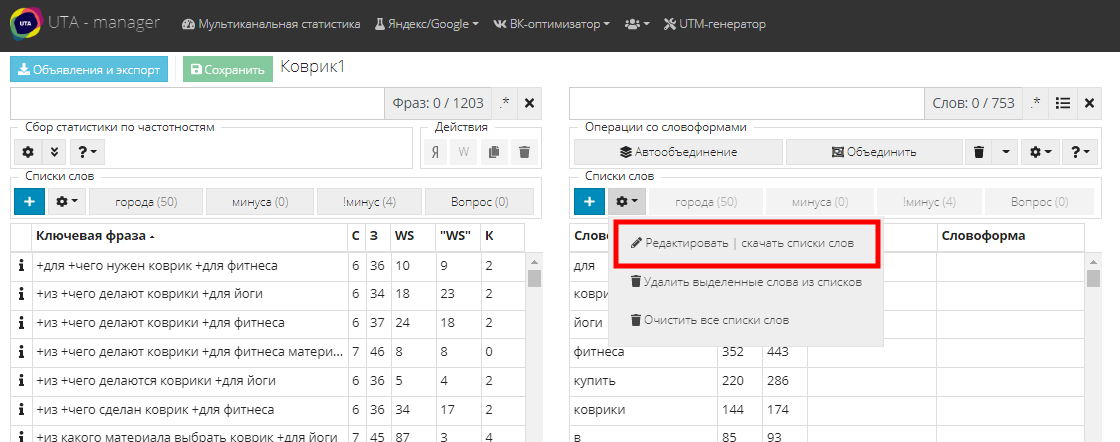
Откроется меню, в котором можно изменить название списка, нажав на карандаш (1), скачать в нужном формате (2), удалить совсем (3) либо не отображать его на панели (4):
Выделяем товары, которых нет в наличии
Это могут быть фразы по непрямым конкурентным товарам. Например, в нашем случае это могут быть коврики из других материалов, которые близки по качеству к нашим. Конечно, в этом случае у вас должен быть план, как переубедить клиента брать то, что он ищет. Этот тип фраз также не рекомендуем использовать на старте рекламной кампании. Их можно использовать в качестве эксперимента с целью расширения охвата.
Использование собранных списков
Мы собрали немало разных списков, которые теперь нужно применить, чтобы они отфильтровались от целевых фраз. Для этого в таблице групп жмем кнопку “Параметры”:
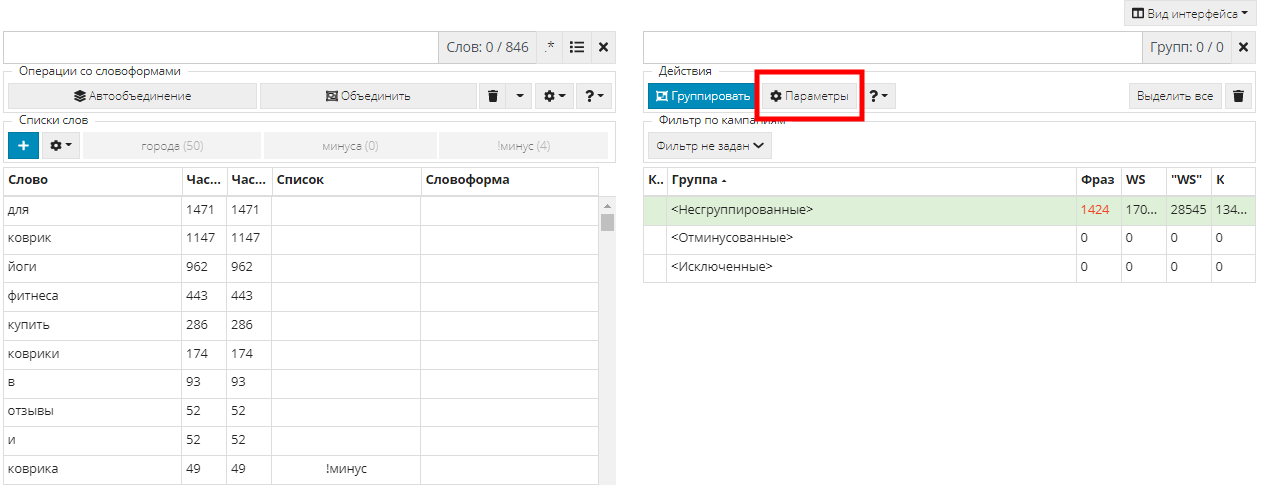
Откроется меню параметров группировки. Параметры, расположенные с левой стороны, пока не трогаем. Справа в настройках условий группировки ставим галочку “Группировка на основе слов из выбранных списков”(1). Затем жмем “Настроить списки слов” (2) и в появившемся окне добавляем все списки, нажав на “+”:
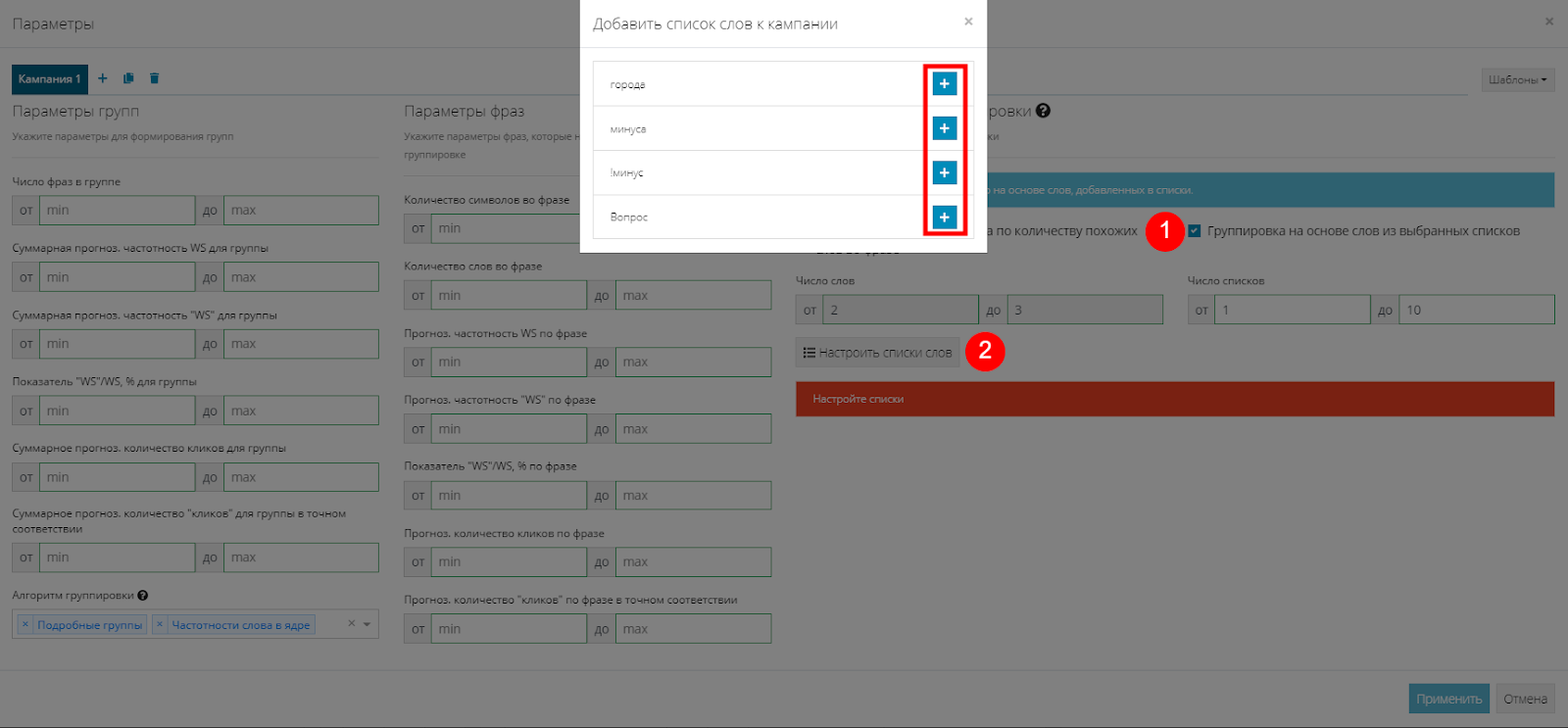
Затем напротив каждой группы меняем “Группообразующий” на “Минус-слова”, выбрав их из списка (1). Затем жмем "Применить".
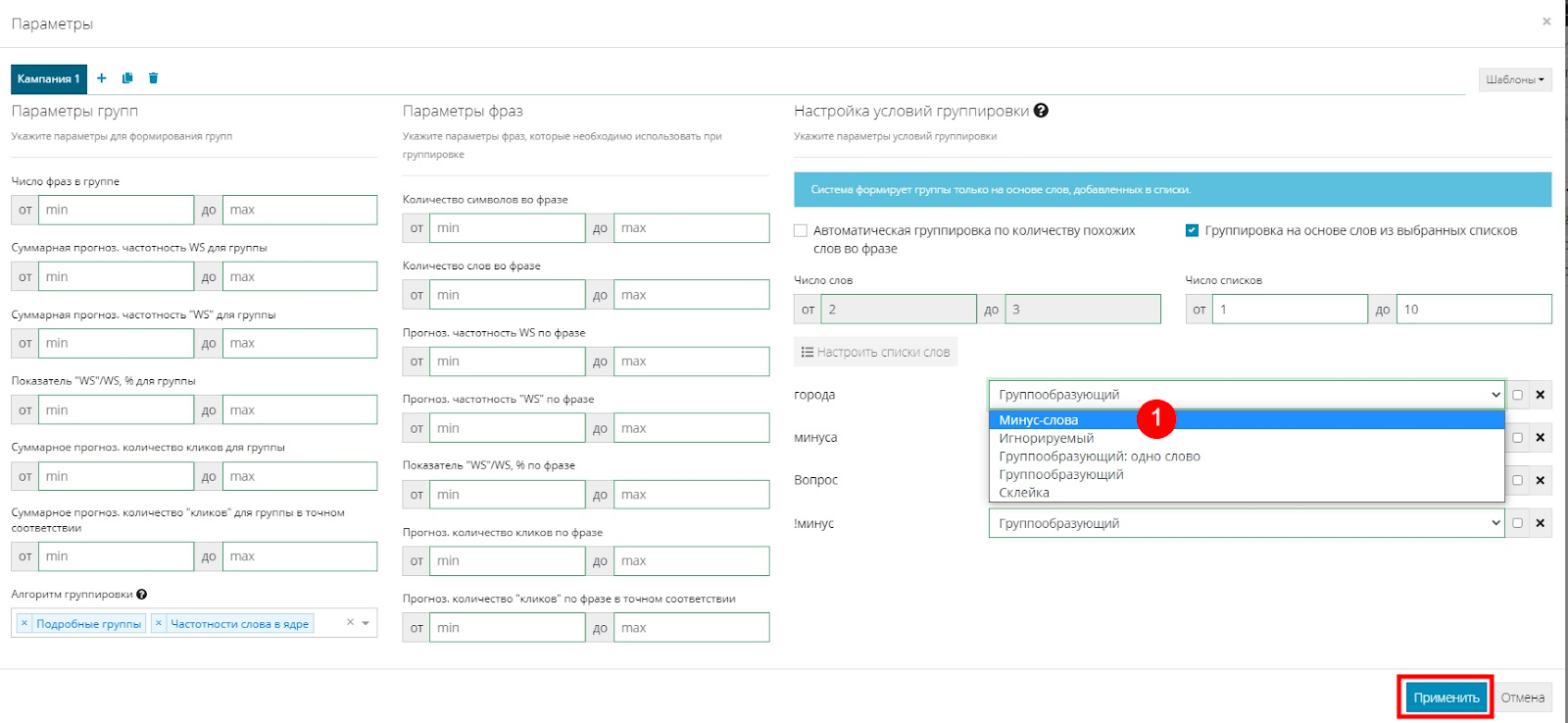
После этого нажимаем кнопку “Группировать”, и фразы из списков отфильтруются в Отминусованные. Теперь осталось разобраться с остальными фразами.
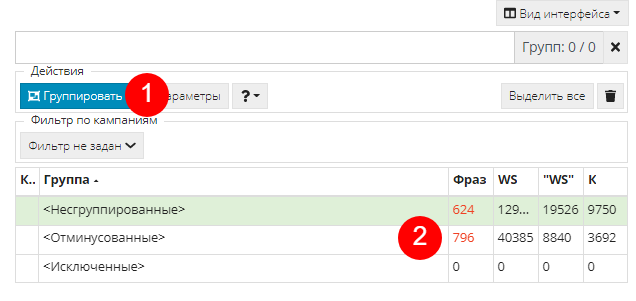
Фильтрация фраз с нулевой частотностью
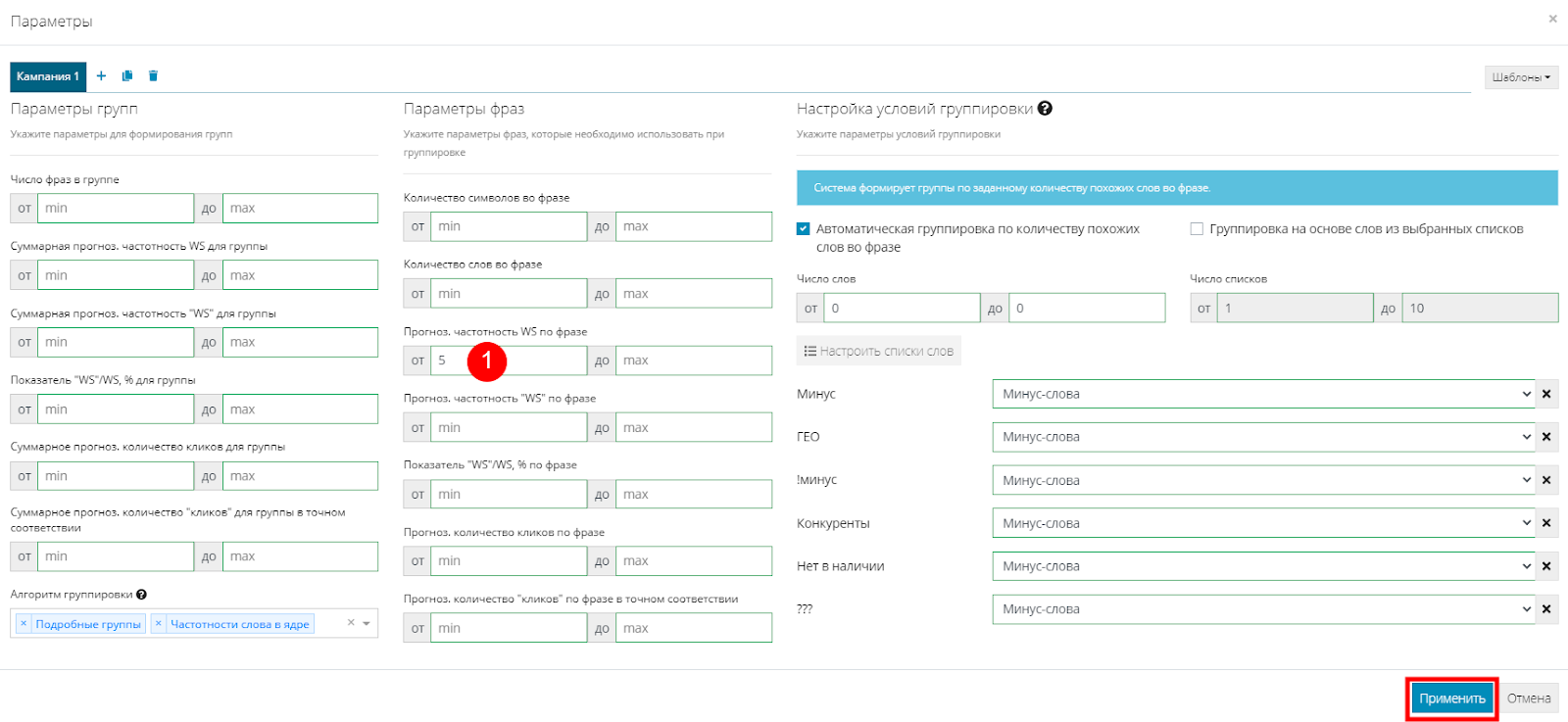
Так как мы собрали статистику частотности фраз по всей России, использовать фразы с очень малой частотностью на старте рекламных кампаний не имеет смысла. В дальнейшем для расширения семантики имеет смысл их добавить, но сейчас для тестовой кампании обойдемся без них. Для этого снова переходим в параметры группировки. В столбце "Параметры фраз" находим параметр “Прогноз частотность WS по фразе” и ставим от 5 (1). Жмем "Применить":
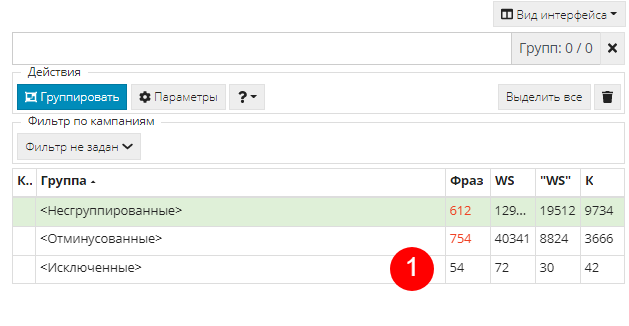
Возращаемся к группировкам и жмем “Группировать” или быструю клавишу R. Видим, что 54 фразы отфильтровались в исключенные (1):
Группировка целевых фраз
Допустим, мы избавились от всех нецелевых фраз, и следующим этапом будет их группировка по смыслу. Сделать это можно в автоматическом и ручном режиме с помощью списков. Рассмотрим оба варианта.
Автоматическая группировка
Переходим в параметры группировки и ставим галочку на “Автоматическая группировка по количеству похожих групп в фразе” (1). В строке "Число слов" указываем на сколько похожих слов должна опираться система при группировке. В нашем случае ставим от 0 до 5 (2). Далее выбираем алгоритм группировки (3). Есть несколько видов алгоритмов, также можно комбинировать их между собой. Описание вызывается по нажатию на знак “?”. В большинстве случаев достаточно установленной по умолчанию комбинации “Подробные группы” и “Частотность слова в ядре”. Оставляем именно так. Затем в параметрах групп устанавливаем предел частотности для группы, чтобы в дальнейшем не получить статус “Мало показов” для группы. Выставляем значение от 30 (4). Жмем “Применить”:
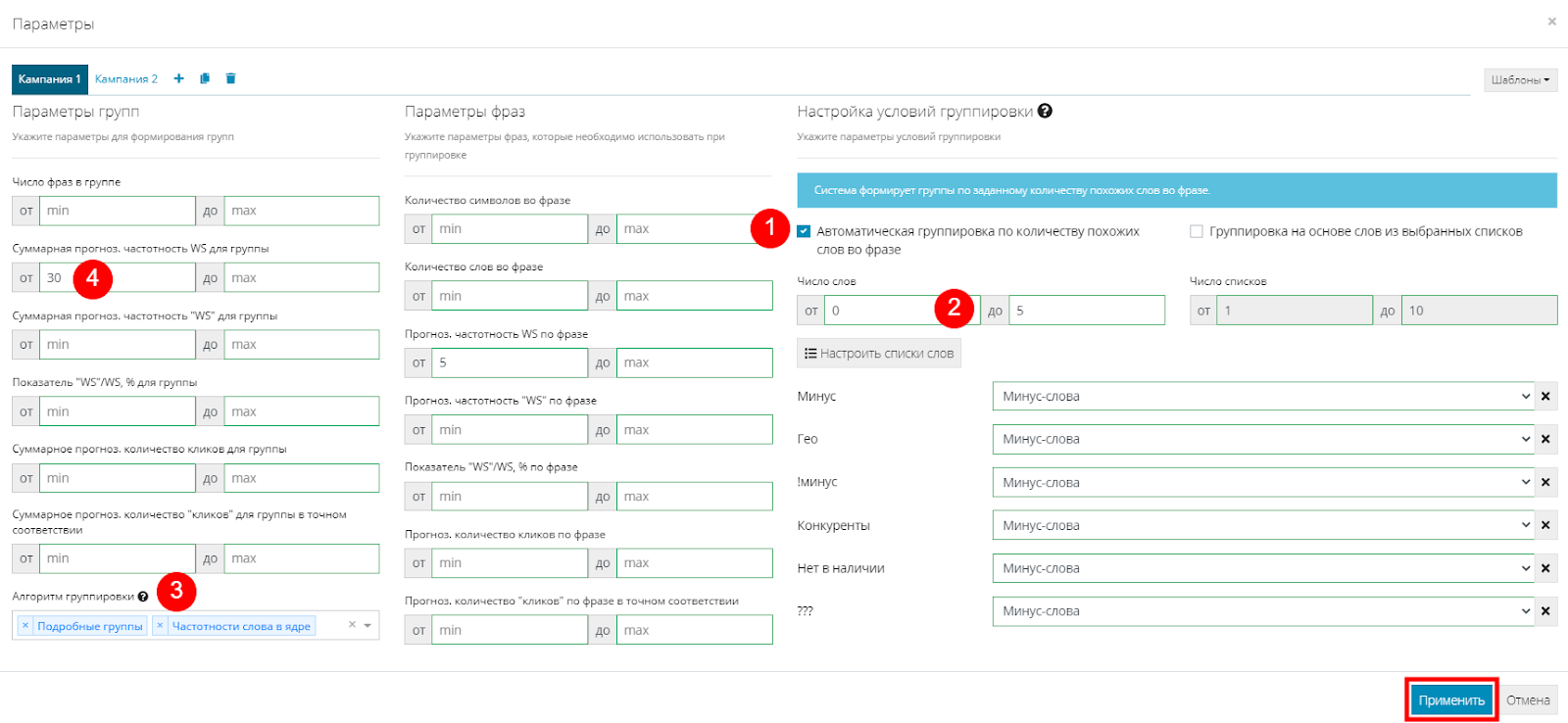
Жмем “Группировать” и видим, что получилось 173 группы с частотностью более 30. Система использовала комбинации всех похожих слов.
Исключение некоторых слов из группообразующих
Название групп формируется из тех слов, что участвовали в группировке. Замечаем, что в группировке участвовали и предлоги. Такие как “для”, “в” и др. Это нам не нужно, поэтому добавим такие слова в игнорируемые при группировке. Для этого выделяем все группы с зажатой клавишей SHIFT и переходим в многострочный фильтр. Там выбираем набор “Стоп-слова” и жмем "Применить":
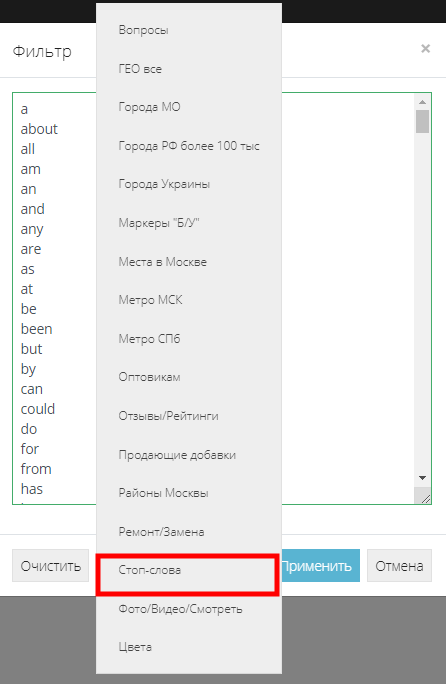
Добавляем все найденные слова в новый список, назовем его “Игнор”. Затем снова переходим в параметры группировки и добавляем этот список, при этом в его параметрах выбираем статус “Игнорируемый”. Жмем "Применить":
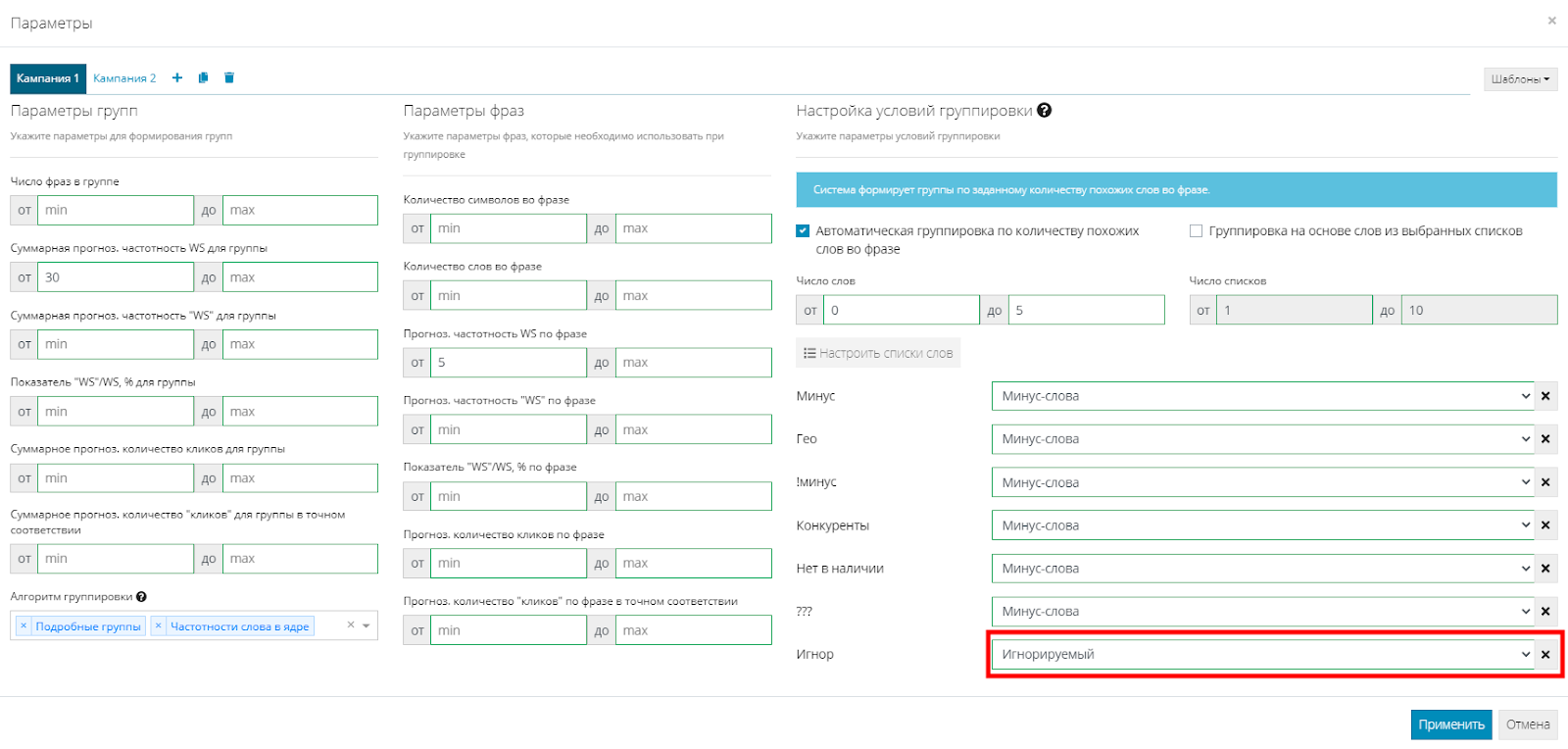
Возвращаемся обратно, жмем “Группировать” и видим, что количество групп сократилось, и предлоги ушли из группировки.
Почему в некоторых группах есть фразы с разным смыслом
Проверяя группы, можно заметить, что в некоторых общих группах есть слова с разным смыслом. Например, у нас это группа йоги/коврики. В ней имеются слова разные по смыслу, но обратите внимание на их частотность - она у всех ниже 30. Поэтому они не удовлетворяют условиям и были отнесены к общей группе по словам "йоги" и "коврик".
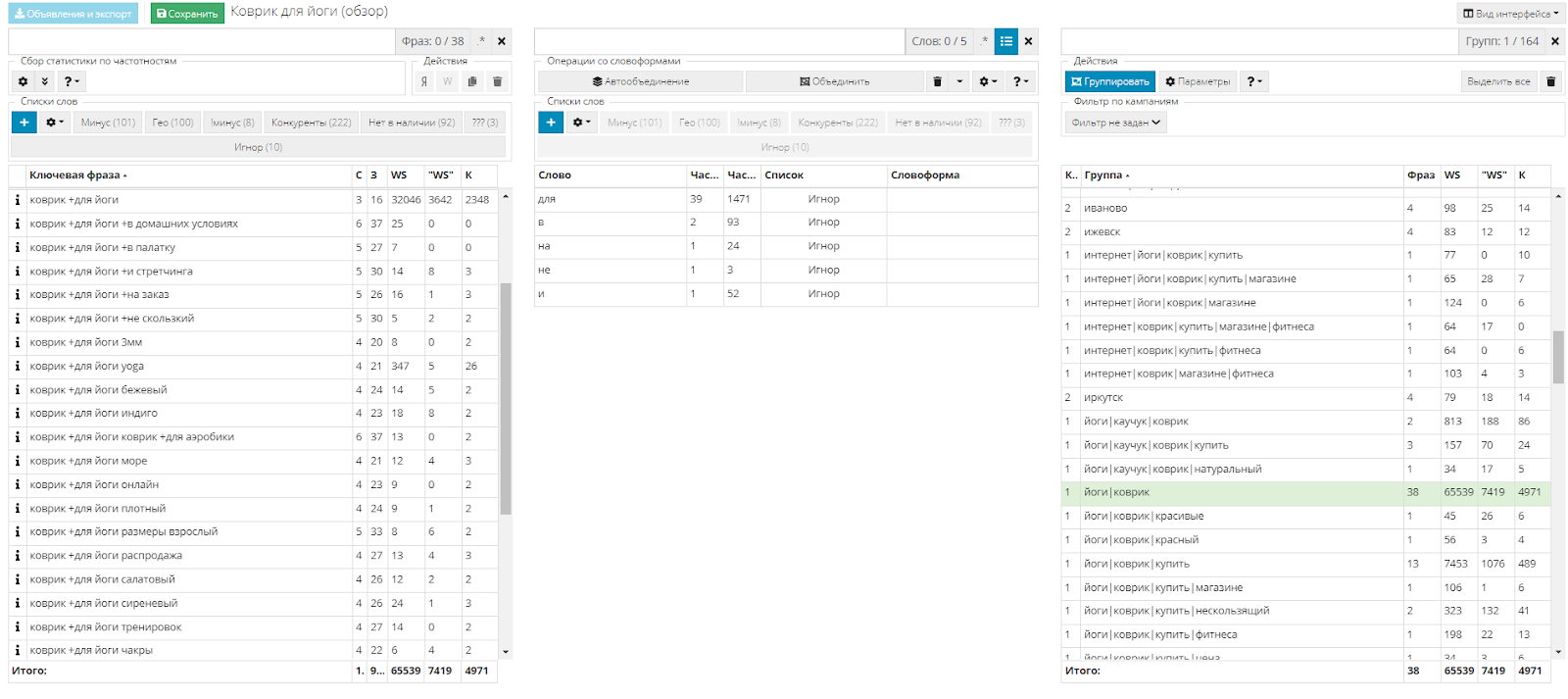
Чтобы сделать эту группу максимально релевантной к запросам пользователей, при составлении объявления в первом заголовке мы используем шаблон ##, который будет подставлять фразу, по которой сработало объявление в заголовок. А так как мы используем лендинг, для всех объявлений будет одна посадочная страница. Это не противоречит правилам настройки.
Ручная группировка
Этот способ группировки может быть более точным. Здесь мы сами выбираем по каким словам группировать фразы. Для этого нужно составить списки слов и добавить туда нужные слова. Это могут быть слова по свойствам.
Например:
- по цвету, размеру, материалу и т.д.
- по применению: для йоги, спорта.
- по использованию продающих добавок: недорого, заказать и т.д.
Если до этого Вы составляли карту запросов, то можете опираться на ее столбцы и составить похожие списки слов.
Затем заходим в параметры группировки и ставим галочку только на “Группировка на основе слов из списка” (1). Добавляем новые списки слов и выставляем им статус “Группообразующий”. Обратите внимание, что рядом со статусом есть пустой чекбокс (2). Поставив галочку в нем, вы обяжете систему использовать слова из указанного списка в каждой группе. Это нужно делать, когда в списке слов есть обязательные для группы фразы. Сейчас нам это не нужно, поэтому пропускаем этот шаг и жмем "Применить". Все остальные настройки остаются прежними.
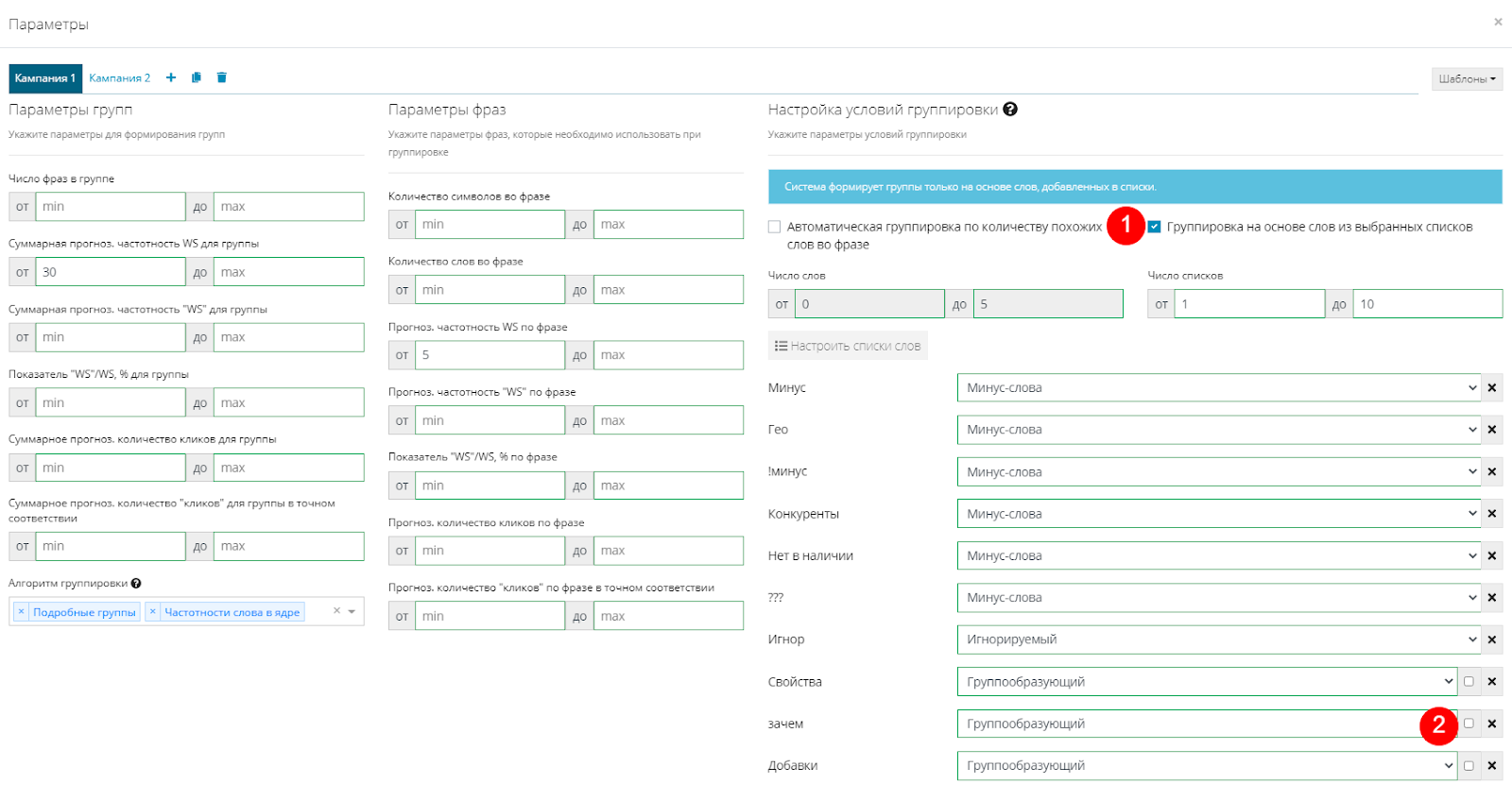
В результате получим группировку по комбинациям слов из указанных списков.
Как выделить некоторые фразы в отдельную кампанию
Ранее мы собирали списки слов по городам, конкурентам и товарам не в наличии. Теперь можем сделать отдельную кампанию для каждого из этих списков. Для этого переходим в настройки группировки. Сверху видим “Кампания 1”, жмем на значок "Копировать" и появляется кампания 2 (1). Это копия таких же настроек, но для другой кампании. Работает это так - на первом шаге для кампании 1 сработают все указанные там условия группировки. На втором шаге, то есть для кампании 2, указанные настройки сработают для оставшихся фраз, то есть в нашем случае, для отминусованных и исключенных. Поэтому, чтобы сделать кампанию по гео-запросам, мы просто меняем статус “Гео” на "Группобразующий" и ставим галочку в чекбоксе, обязуя систему брать слова только из этого списка (2). Обращаю внимание, что пример показан на основе ручной группировки.
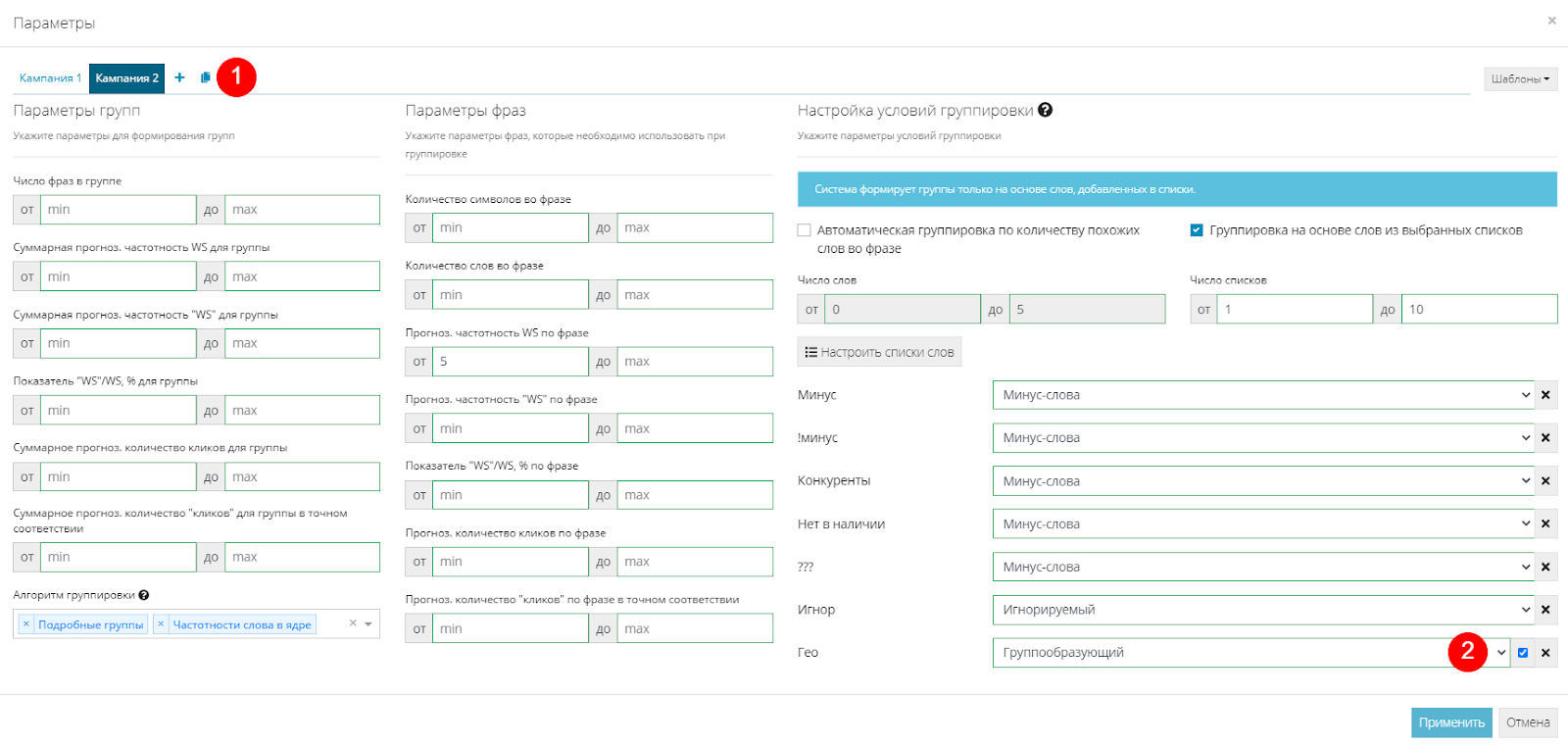
Теперь жмем “Группировать” и видим, что появились новые группы в списке по каждому городу. Отсортировать группы можно нажав на “к” (1) либо воспользоваться фильтром для кампаний (2).
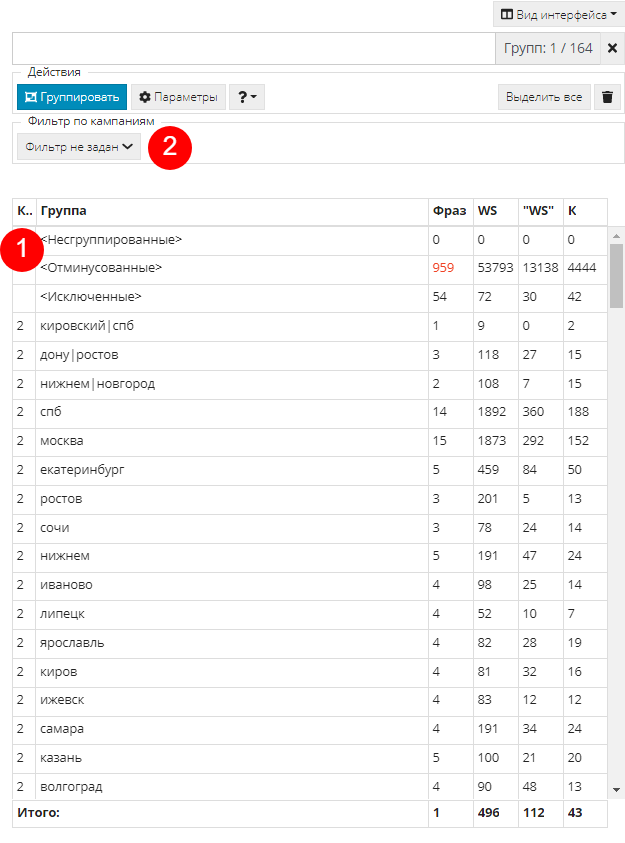
Аналогичным образом можете проделать это для списка конкурентов или товаров не в наличии.
Экспорт в Excel
Перед тем как выгружать данные в файл, нужно сохранить проделанную работу. Для этого нажмите “Сохранить” в верхнем левом углу (1). Кстати, не забывайте делать это почаще, ведь если Вы обновите страницу, не сохранив изменения, то всю работу придется делать заново. Затем жмем "Объявления и экспорт" (2):
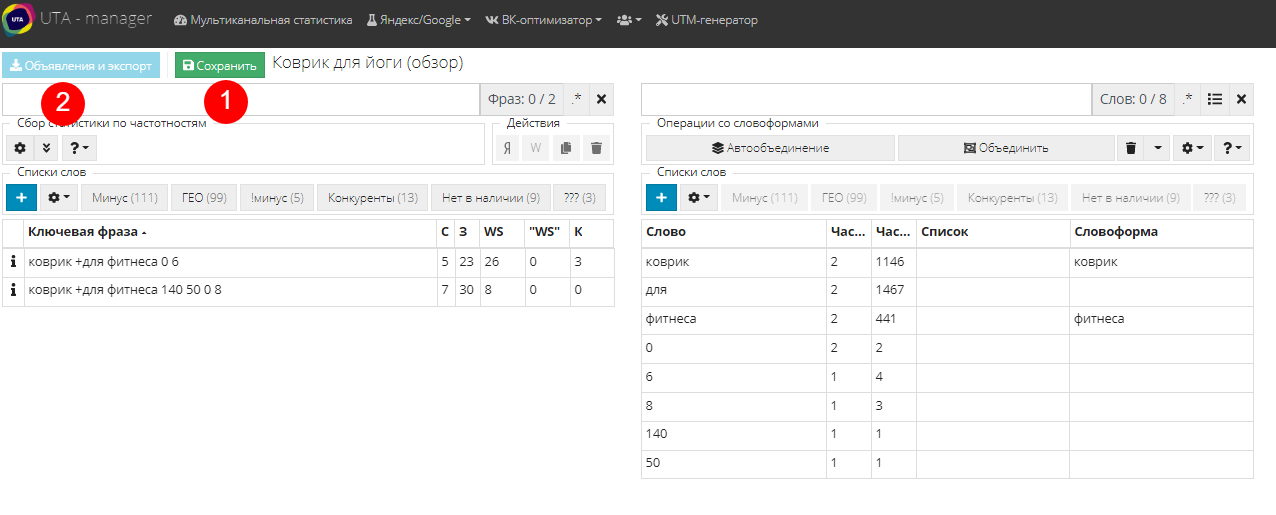
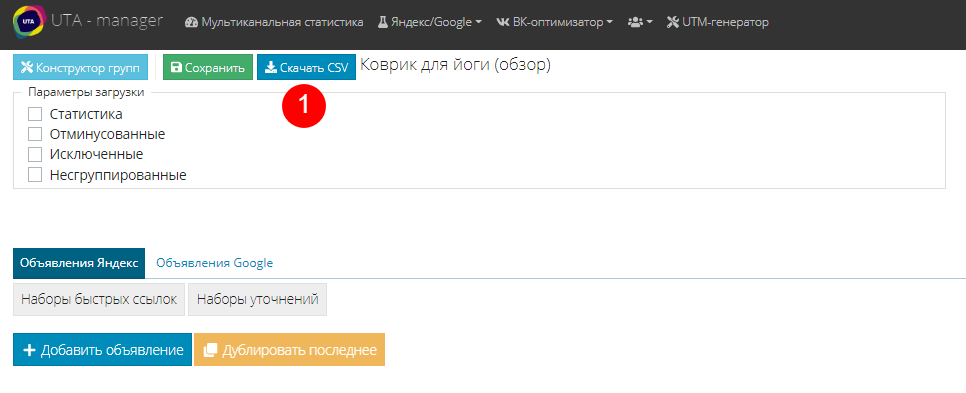
Откроется новое окно, где самым простым действием будет выгрузка данных в excel-файл. Ставим галочку напротив нужного варианта и жмем “Скачать CSV” (1). Статистика - это выгрузка сгруппированных ключевых фраз с той статистикой, которая была собрана в проекте. Остальные - это отминусованые, исключенные и несгруппированные, которые позволят выгрузить фразы из одноименных списков.
Как озаглавить слова из списка
Так как в некоторых группах будет использоваться шаблон для первого заголовка, нужно позаботится о правильном написании используемых ключевых фраз. Например, у нас есть группа слов со всеми городами, но названия городов во всех фразах пишутся с маленькой буквы. В этом случае выбираем в соответствующем поле нужный список с городами (1). Теперь, если во фразе используется слово из этого списка, оно будет писаться с заглавной буквы. Также этой функцией удобно пользоваться для имен собственных, названий брендов и тому подобных слов.
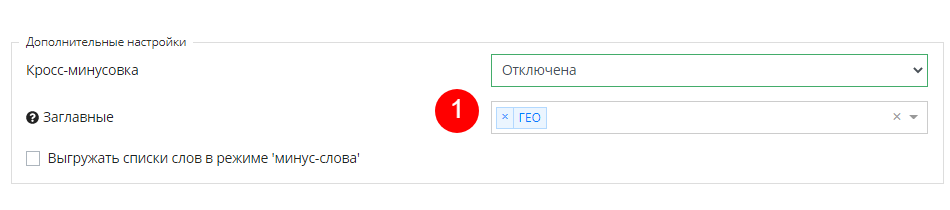
Выгрузка минус-слов с точной словоформой (!)
Ранее мы создали список минус-слов, которые нужно использовать в точной словоформе. Чтобы не делать это вручную, в конструкторе UTA-manager встроена возможность выгружать минус-слова с восклицательным знаком. Для этого ставим галочку в соответствующее поле (1) и выбираем нужный список слов^
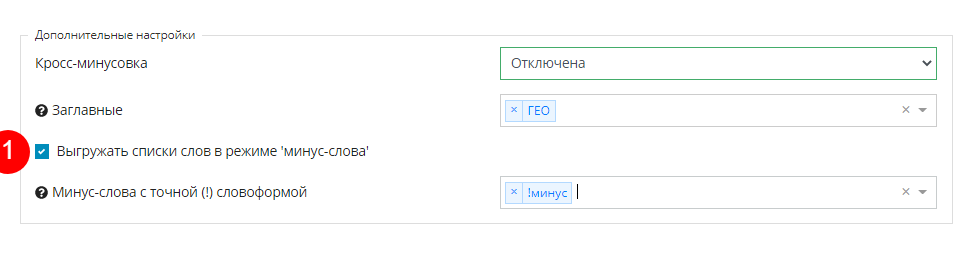
Составление объявлений
Пришло время создавать релевантные объявления. Конструктор позволяет делать это в автоматическом режиме. Есть возможность создание объявлений, как для Яндекс.Директ, так и для Google Ads. Мы создаем кампанию для Директа, поэтому выбираем этот вариант и жмем “Добавить объявление”:
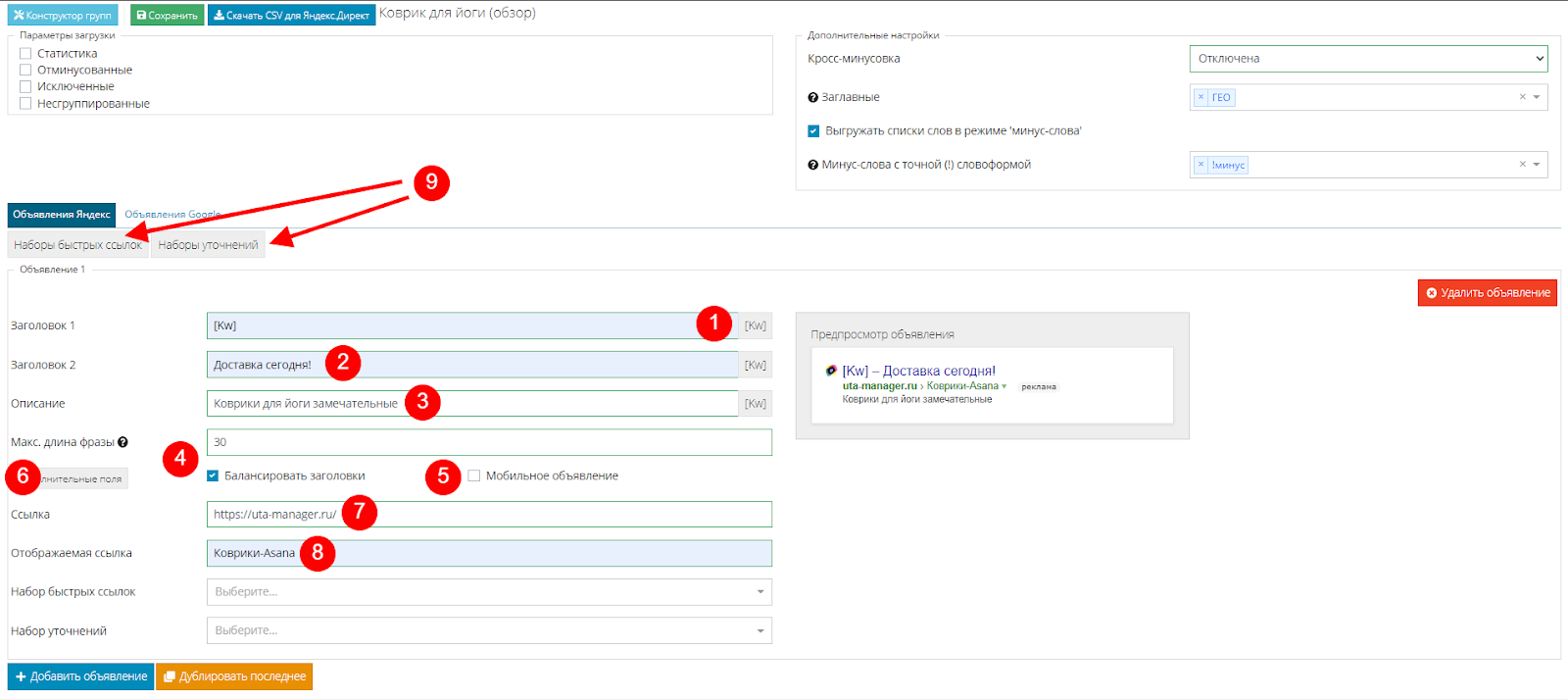
Появится меню создания, где нужно заполнить свободные поля. Так в заголовке 1 указываем шаблон [Kw] (1), который означает, что в заголовок будет добавлена самая оптимальная фраза из группы. То есть конструктор выбирает самую запрашиваемую фразу, учитывая при этом общую частотность фраз, частотность фраз в точном соответствии (в кавычках) и частотность с восклицательным знаком.
Далее заполняем второй заголовок (2) и описание (3).
Затем указываем максимальную длину используемой фразы. По умолчанию стоит 30. В этом случае конструктор будет стремиться выбрать фразу не длиннее 30 символов. При этом, если все фразы в группе будут длиннее, при выгрузке в Директ Коммандер появится ошибка, и нужно будет вручную укорачивать заголовок. Также можно балансировать первый и второй заголовок. В этом случае конструктор разделит фразу на слова и то, что не поместилось в первый, отправит во второй заголовок. Для этого ставим галочку в чек бокс (4).
Если хотите чтобы объявлению присвоился статус мобильного, отмечаем это в другом чекбоксе (5).
Затем вызываем дополнительные поля (6) и указываем ссылку на посадочную страницу (7) и отображаемую ссылку (8).
После этого нужно добавить быстрые ссылки и уточнения. В конструкторе это делается не по одному, а целыми наборами. Чтобы добавить набор, нажимаем на одну из соответствующих кнопок (9).
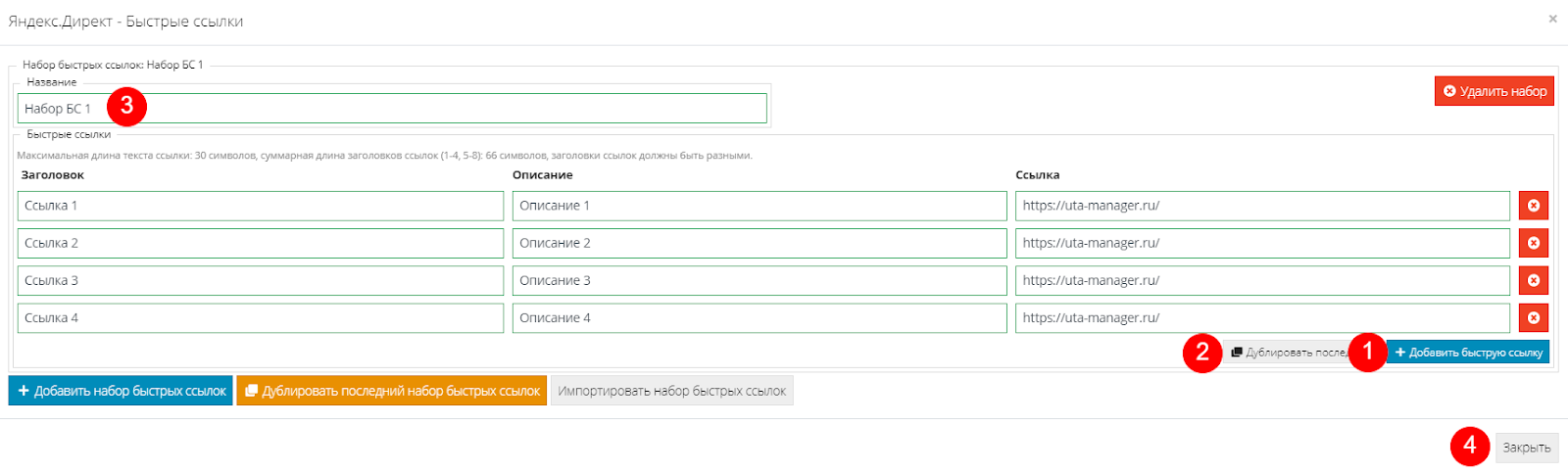
Появится меню с предложением добавить новый набор или импортировать набор из другого проекта, к которому есть доступ. Выбираем “Добавить новый набор быстрых ссылок”. Откроется меню, где заполняем поля заголовков, описания и ссылок.
Если нужно добавить дополнительные быстрые ссылки, то жмем на соответствующую кнопку(1). Также можно дублировать последнюю ссылку (2). По правилам Яндекс.Директ можно добавить не более 8 ссылок.
Если нужно, указываем имя для набора (3) и жмем “Закрыть” (4):
Похожие действия выполняем и с набором уточнений.
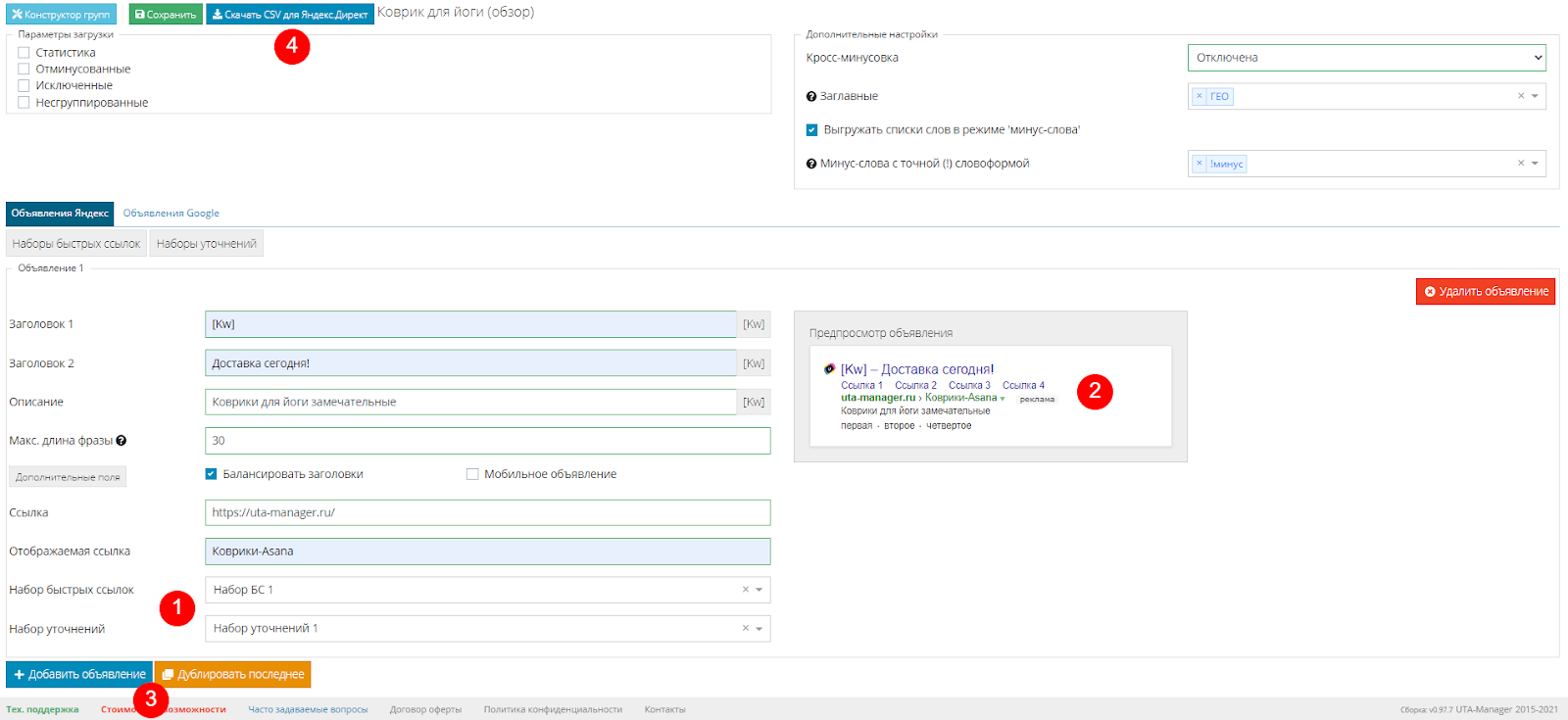
После этого осталось выбрать эти наборы в дополнительных полях (1).
На экране предпросмотра показано, как будет выглядеть объявление без учета подстановки фразы в первый заголовок (2).
Далее можно либо добавить следующее объявление в группу для А/Б теста, либо дублировать последнее (3).
Для окончания работы с конструктором скачиваем полученные CSV-файл, нажав на соответствующую кнопку (4):
Завершающий этап
Скачанный файл можно просмотреть в Excel и при необходимости отредактировать некоторые заголовки. Подробнее об этом здесь. А можно сразу загрузить его в Директ Коммандер и сделать это там. В нем указываем нужные параметры для кампаний, такие как регионы показов, стратегию ставок и их корректировки. Делаем кросс-минусовку, выставляем ставки для фраз и другие необходимые действия.
После этого готовую кампанию можно выгружать в Яндекс.Директ. Руководство с пошаговыми действиями здесь.
Вывод
Подобный подход к настройке кампаний позволяет сократить трудозатраты в 10 раз.
На этапе чистки семантического ядра от мусора существенно экономится время за счет уникальных алгоритмов работы, удобного интерфейса конструктора, а также заготовленных наборов слов для фильтрации.
Группировка фраз может производится, как в моментальном автоматическом режиме, так и с помощью собственных списков фраз. И не идет ни в какое сравнение с ручной группировкой в Excel, а также другими сервисами, например Key Collector.
Объявления создаются в автоматическом режиме, при этом заголовки получаются релевантны смыслу группы ключевых фраз.
В дальнейшем интерфейс и возможности конструктора будут совершенствоваться, и работать с ним станет еще удобнее.